Z-Image: 6B 参数的单流 S3-DiT 效率革命
Z-Image: 当 6B 小钢炮
跑赢 80B 重型卡车
一定要 80B 参数才能画出顶级图像吗?Z-Image 用 "S3-DiT 单流架构" 告诉你: Less is More, Unified is Better.
🏎️ 1. 直觉先行:当“大”不再是唯一的答案
大家好,欢迎来到生成式 AI 的“后大模型时代”。如果把 AI 竞赛比作 F1 赛车,过去两年的主旋律只有一句糙话:“力大砖飞” (Scale at all costs)。
无论是 Hunyuan-Image (20B+) 还是 Flux.1 (12B),大家的思路出奇一致:想要画得更好?那就加参数!想要懂更多概念?那就堆数据!于是我们看到了一个个“显存黑洞”——模型越来越大,大到只有巨头跑得起,大到一张 H800 都要喘半天粗气。
Gemini的“灵魂发问”
但在 2025 年的今天,我们必须停下来问一个反直觉的问题:
如果一台 6 缸引擎(6B 参数)经过极致的空气动力学设计(架构优化)和顶级燃油(数据清洗),能不能跑赢那台笨重的 12 缸怪兽?
Z-Image 给出的答案是:不仅能赢,而且赢得更漂亮、更便宜。
❌ 巨人的困境 (The Goliath Trap)
目前的 SOTA 模型(如 SD3, Flux)普遍采用 Dual-Stream(双流架构)。它们就像是一个精神分裂的巨人,左脑(Text Encoder)处理文字,右脑(DiT)处理图像,中间隔着千山万水,只能靠传纸条(Cross-Attention)沟通。
后果:
1. 贵: 动辄 20B 参数,显存爆炸。
2. 慢: 信息交互效率低,需要更多步数。
✅ 大卫的策略 (The David Strategy)
Z-Image 选择了 Single-Stream(单流架构)。它把文字和图像当成“一家人”,直接拼接成一条序列塞进 Transformer。
优势:
1. 密: 每一层都在进行深度的模态融合。
2. 省: 6B 参数就能达到 SOTA 效果,显存占用砍半。

📊 震撼业界的数字:$628K
这不是这篇论文的版面费,而是 Z-Image 整个预训练流程的总成本。
相比之下,训练一个同级别的 Llama-3 或 Flux Pro 可能需要数百万美元。
仅用 314k H800 GPU 小时,Z-Image 就向世界证明:Efficiency is the new Scale(效率即是新的规模)。
Z-Image 的成功不是偶然,而是一场蓄谋已久的“降维打击”。它通过逻辑链条 架构统一 (Single-Stream) + 数据纯净 (Data Profiling) + 蒸馏加速 (Turbo),把高不可攀的 AI 绘画大模型拉下了神坛。
接下来,我们要像剥洋葱一样,一层层揭开它的核心机密。首先,让我们穿越回五年前,看看这一切是怎么开始的。
🧬 2. 演化史:从异地恋到心神合一 (The Evolution)
第一幕:异地恋的烦恼 (The Cross-Attention Era)
故事开始于 2022 年。那时的霸主是 Stable Diffusion 1.5。 它的架构设计非常经典,但也极其“分裂”。它由两个完全独立的大脑组成:
- 左脑 (Text Encoder): CLIP ViT-L/14。它是一个死记硬背的书呆子,负责把你的 Prompt 压缩成一个 768 维的向量。
- 右脑 (Image Generator): U-Net (860M 参数)。它是一个只会画画的画家,通过 Cross-Attention 接收左脑的指令。
🚧 瓶颈:Cross-Attention
这种机制就像“写信”。左脑把千言万语压缩成一封只有 77 个 Token 的信。 右脑读到 "Red Box left of Blue Ball" 时,经常因为信里信息压缩过度,画成 "Red Ball left of Blue Box"。 这就是著名的“属性错位” (Attribute Bleeding) 问题。
🩹 SDXL 的补丁:暴力美学
2023 年的 SDXL 并没有改变“异地恋”的本质,而是选择了“把信写长”。
它引入了双文本编码器 (Dual Text Encoders):CLIP + OpenCLIP-G。
向量维度从 768 暴涨到 2048。
U-Net 参数量也堆到了 2.6B。
结果:
虽然理解力提升了,但架构依然是分离的。文字和图像从未真正“见过面”。
第二幕:昂贵的双人舞 (The Dual-Stream Era)
为了让文字和图像更好地交流,Stable Diffusion 3 (SD3) 和 Flux.1 开启了“双流”时代。 它们抛弃了 Cross-Attention,改用更复杂的 Transformer 架构。
SD3 MM-DiT: 貌合神离
SD3 提出了 Multimodal Diffusion Transformer (MM-DiT)。
机制: 它有两套独立的权重(Weights),一套给文本,一套给图像。
虽然它们在 Attention 层会交换信息,但本质上还是两个“人格”。
这就像两个人坐在一张桌子上办公,偶尔互相看一眼对方的屏幕。
Flux.1 Hybrid Stream: 先分后合
Flux 更进一步,设计了 Double-Stream Block 和 Single-Stream Block 的混合体。
1. 前段 (Double): 文本和图像各跑各的,通过 Concatenation 计算 Attention,但权重不共享。
2. 后段 (Single): 把两者强行融合,用一套参数处理。
代价: Flux 12B 的参数量极其庞大,推理显存需求极高(24GB 起步)。
Hunyuan Mixture of Experts: 只有土豪玩得起
腾讯的混元 (Hunyuan-Image) 走到了极致。
80B 参数! (你没看错,800亿)。
为了跑得动,它用了 MoE (混合专家模型)。64 个专家网络,每次只激活其中的 ~13B。
这就像雇佣了一个 64 人的专家团队,每次只叫 10 个人出来干活。
缺点: 训练成本是天价 (>$2M)。
第三幕:心神合一 (The Single-Stream Revolution)
Z-Image 掀桌子了。 为什么一定要把文字和图像分开?为什么不能把它们看作是同一种语言?
它继承了 DiT (Diffusion Transformer) 和 SiT (Scalable Interpolant Transformer) 的衣钵, 并将其推向了极致:S3-DiT (Scalable Single-Stream DiT)。
Output = Transformer(Sequence)
核心魔法:3D-RoPE
如果把文字和图像混在一起,模型怎么知道谁是谁?
Z-Image 发明了三维位置编码:
x, y: 图像的空间坐标。
t: 文本的序列位置。
这让模型在同一个大脑里,既有了“空间感”,又有了“语序感”。
💡 为什么叫 “Z” Image?
虽然论文没有明说,但我们可以猜测:Z 可能代表 Z-axis (深度/第三维度)。 传统的 RoPE (旋转位置编码) 是 2D 的 (x, y)。而 Z-Image 引入了 3D-RoPE, 将文本序列视为第三个维度 $t$,从而在数学上完美统一了时序(文本)和空间(图像)。 这是 S3-DiT 能够高效运作的数学基石。
🗺️ 3. 方法论:Z-Image 的核心魔法 (Methodology)
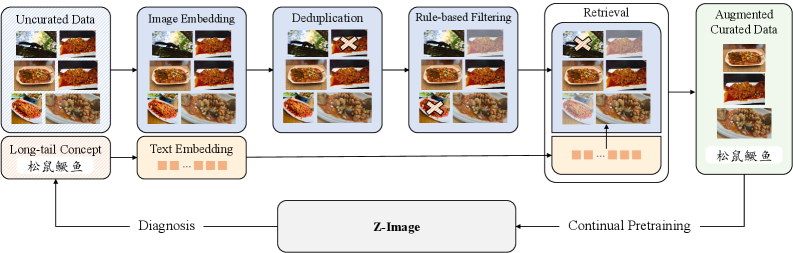
3.1 数据工程:原油提炼厂 (The Data Refinery)
Z-Image 的核心哲学是:“Scaling data quantity is easy; scaling data quality is hard.” (堆量易,提质难)。
它构建了一个包含四个引擎的庞大清洗系统,我们可以把它想象成一个“原油提炼厂”,把充满杂质的互联网数据(原油)一步步提炼成高辛烷值的航空燃油(Golden Data)。
1. Profiling (画像) = 粗滤网
测量数据的“生命体征”:分辨率、美学评分、噪声水平。 就像把含水量太高或杂质太多的原油直接剔除。
2. Vector (向量) = 同质化去除
利用 Embedding 向量聚类。互联网上 90% 的“梗图”是重复的。 必须防止模型“过拟合”到这些重复样本上。
3. Graph (图谱) = 知识编织
构建概念树(Ontology)。 确保模型不仅看过“狗”,还看过“哈士奇”、“柴犬”、“金毛”。 这是为了解决长尾分布 (Long-tail) 问题。
4. Active Curation (主动策展)
最强一招。 系统会先试着生成,发现画不好“松鼠鳜鱼”,就针对性地去网上抓取 500 张松鼠鳜鱼的图来“补课”。 这叫“缺啥补啥”。
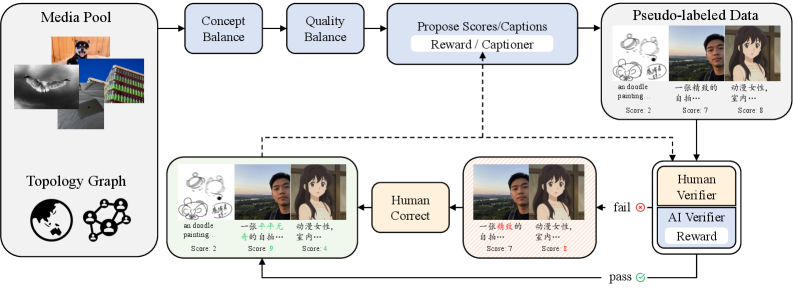
🔍 深度解剖:超级标注器 (Z-Captioner)
Z-Image 的秘密武器还有一个强大的 VLM 标注器。它不仅能写出“这是一个苹果”,还能识别图片里的文字 (OCR) 和深层常识 (World Knowledge)。

世界知识识别 (World Knowledge)
认出 "Big Ben" 而不是 "Clock Tower"

OCR 文字提取
精准提取画面中的文本信息
3.2 课程学习:精英教育三部曲 (The Elite Education)
传统的训练是一股脑把数据喂进去。Z-Image 采用了一种“Omni-Pre-training” (全能预训练) 的课程表。 这就像人类的教育体系:小学学常识,中学学技能,大学搞科研。
阶段一:Low-Resolution Bootstrapping
核心逻辑: 学习“猫有两只耳朵”不需要 4K 画质。在 256x256 的低分辨率下,模型可以极快地看过海量数据,学会物体关系。 这就像小学教育,先识字,不求书法漂亮。
阶段二:Omni-Pre-training (Multi-Task)
开始引入多分辨率桶 (Bucket)。关键是加入了 Joint I2I (图生图) 任务。 让模型看“修图前”和“修图后”的对比,学会“把红苹果变成青苹果”这种动态指令。
阶段三:High-Quality Polish
引入 Prompt Enhancer (提示词增强器) 生成的合成数据。
这是为了解决 6B 模型“想象力匮乏”的问题。PE 会把简单的 "A cat" 扩写成一段华丽的描写,教 S3-DiT 画出那种 ArtStation 风格的精美图片。
3.3 核心机制:时空导航系统 (3D-RoPE)
⚙️ 工程师笔记:如何在 Transformer 里装 GPS?
在一个 Transformer 里同时处理一维文本 ($T$) 和二维图像 ($H, W$),位置编码是个大难题。
传统的 RoPE (Rotary Positional Embedding) 是 1D 或 2D 的。Z-Image 必须发明 3D-RoPE,才能让模型不“迷路”。
编码图像的 (x, y) 坐标。
让模型知道“猫头”在“猫身”的上面。
编码文本序列的 t 位置。
让模型知道“Red”是修饰“Apple”的。
技术总结: 3D-RoPE 成功地解耦了空间和时间,让 Image Tokens 可以自由地在 2D 空间延展,而 Text Tokens 在时间轴上延展,两者互不干扰却能紧密互动。
🥊 4. 实验验证:大卫 vs 歌利亚
Z-Image (6B) 面对的是一群体重是它 3-10 倍的对手:Hunyuan (80B) 和 Flux.1 (12B)。
这不是一场公平的决斗,而是一场“效率”的屠杀。
在 GenEval 和 DPG-Bench 等权威基准测试中,Z-Image 证明了:
Scaling Law 并不是唯一的真理。
| 模型 (Model) | 参数 (Params) | 架构 (Arch) | 训练成本 (Est.) |
|---|---|---|---|
| Hunyuan-Image | 80B (MoE) | Dual-Stream | >$2,000,000 |
| Flux.1 [Pro] | 12B | Hybrid | >$1,000,000 |
| Z-Image | 6B | S3-DiT | $628,000 |
4.1.2 实战:眼见为实 (Visual Evidence)
仅仅看跑分是不够的。下图展示了 Z-Image (最右侧) 与其他 SOTA 模型的直观对比。 可以看到在光影质感和细节纹理上,6B 的 Z-Image 完全不输 80B 的巨头。

4.2 能力展示:能文能武的六边形战士
🔤 “文盲”的终结:双语渲染
Z-Image 最令人震惊的能力是它可以像排版软件一样精准地“写字”。 不仅是英文,连结构复杂的中文汉字都能写对。
- Single-Stream 优势: 文字 Token 直接作为图像 Token 的“邻居”。Attention 机制让像素点直接“看到”字母的笔画结构。
- OCR 数据集: 它是“看着书长大的”。训练数据中包含了大量带文字的海报、书籍封面。

🎨 听话的画笔:Z-Image-Edit
得益于 Omni-Pre-training 中的多任务学习,Z-Image 不仅能画,还能改。 它可以执行复杂的自然语言指令,而不需要像 SDXL 那样依赖 ControlNet 等外挂。
-> 纹理替换,结构保留
-> 物体添加,空间感知

4.3 唯快不破:解耦蒸馏 (Decoupled DMD)
Z-Image-Turbo 将推理步数从 50 步压缩到了 4-8 步,实现了亚秒级出图。
这背后的黑科技是 Decoupled DMD (解耦分布匹配蒸馏)。
传统的蒸馏往往会让画面变糊(因为强行拟合均值)。Z-Image 的解法是把“画得准”和“画得美”拆开来练。
Inference Latency (H800 GPU)
🛑 5. 祛魅与展望:医疗 AI 的新基石?
看完 Z-Image 的华丽表演,我们必须冷静下来。 对于像我们这样的科研人员(尤其是 Bio-AI 方向),这个模型到底意味着什么?是又一个生成二次元美女的玩具,还是下一代科学模拟器的原型?
⚠️ 警惕:Prompt Enhancer 的副作用
Z-Image 为了弥补 6B 参数的“想象力不足”,引入了 Prompt Enhancer (PE) 来扩写提示词。
在艺术创作中,这是优点。你输入“医生”,它扩写成“帅气的未来派医生...”。
但在科学研究中,这是灾难。 如果病理学家输入“浸润性导管癌 3 级”,PE 可能会为了画面“丰富度”而虚构出淋巴结转移的特征。
🚀 脑洞:Z-WSI (Whole Slide Imaging)
Z-Image 的 Single-Stream (拼接) 架构其实为病理学提供了一个绝佳的思路。 目前的病理 AI 还在用“切片+多示例学习”的笨办法。
核心思路:
- 🔹 输入序列: [病理报告文本] + [WSI 巨型切片 Tokens]
- 🔹 训练目标: 让模型学会“读报告画片子”。
- 🔹 应用: 生成极其罕见的癌症亚型数据,解决医疗长尾问题。
🛠️ 工程师实战指南
import torch from z_image_pipeline import ZImagePipeline# 1. 加载 Turbo 模型 (bf16 省显存) pipe = ZImagePipeline.from_pretrained( “alibaba/z-image-turbo-6b”, torch_dtype=torch.bfloat16 ).to(“cuda”)
# 2. 医疗微调小贴士 (Hypothetical) # pipe.transformer.text_embedder.requires_grad_(False) # 冻结文本理解 # pipe.transformer.visual_embedder.train() # 只训练视觉
# 3. 极速推理 (8 Steps) prompt = “A high-res histology slide of lung adenocarcinoma” image = pipe( prompt, num_inference_steps=8, # Turbo 模式 guidance_scale=3.5 ).images[0]
image.save(“lung_cancer_synth.png”)
📚 Gemini的划重点 (Take Home Message)
Z-Image 的成功不是单点的突破,而是 架构精简、数据提纯、训练科学化 的系统性胜利。 这才是我们应该学习的“第一性原理”。