Qwen-VL 系列发展路径:李宏毅风格超长讲义
导览:这份讲义怎么读?
导览:这份讲义怎么读?
如果把整条 Qwen-VL 发展史想象成一部开放世界 RPG 游戏,那这份讲义就是你的官方攻略书:告诉你主线任务、支线剧情、隐藏 Boss 在哪里,以及每一代版本到底「点了哪些技能点」。
为了方便你快速定位,我们大致按照下面的结构来展开:
背景与动机
说明「为什么需要 Qwen-VL」,解决纯文本模型的哪些痛点。
基础补课
把后面会用到的视觉编码、对齐损失等概念先打好底。
家族谱系
画出 Qwen-VL 家族的「学术谱系树」,看它是怎么从一棵小树苗长成一整片森林。
逐代拆解 Method
核心干货:逐代拆解 Qwen-VL 到 Qwen3-VL 的架构细节与演进逻辑。
实验与数据
看实验结果背后真正值得关注的点,而不是只背数字。
复现与展望
给出复现与工程实践建议,以及未来可能的研究方向。
整个讲解会尽量保持对话感:我会不断抛出「如果我们这样做会怎样?」、「那能不能再贪心一点?」之类的小问题,然后再用直觉 + 公式带你走完全程。
1 一、为什么要关心 Qwen-VL?
1 一、为什么要关心 Qwen-VL?
先想象这样一个场景:你在和一个只会聊天的 LLM 对话,它什么都能解释,但只要你丢一张图片过去,它就瞬间变成「失明的哲学家」——可以聊人生,却看不到世界。
这就是纯文本大模型的典型困境:它们的大脑很大,记忆很强,但输入只有一维的文字,面对现实世界里那种「图文交织」的信息流,会天然缺一块。
而 Qwen-VL 系列想做的事情,就是给这位只会说话的哲学家装上一双眼睛,甚至顺手再加一副 AR 眼镜:不仅能看到画面里的每一个像素,还能理解时间、空间、文本、公式、UI 操作乃至长视频中的因果关系。
如果我们再具体一点,它至少要解决三类现实中的「卡关」问题:
- 看得见但看不懂:传统 OCR 或检测模型可以圈出文字和框,但不知道「问题在哪」,更不知道「下一步该干嘛」。
- 看得懂一张,看不懂一堆:面对长文档、PPT、网页、GUI、视频时,模型无法在几十张甚至几千帧信息之间建立稳定的记忆和推理链。
- 看得懂现在,看不懂历史:很多任务需要结合前文上下文、之前几轮对话、上一个画面中的状态,这就要求模型拥有真正的「长上下文、多模态」能力。
Qwen-VL 系列就是沿着这三个痛点一路升级:从最初的「能看图说话」,到 Qwen2-VL 的「任意分辨率 + 视频 + 多语言」,再到 Qwen2.5-VL 的更强推理,最后是 Qwen3-VL 把上下文、长视频和思考能力都拉到一个新高度。
所以,与其把 Qwen-VL 当成一篇篇独立的技术报告,不如把它们看成是一条逐渐升级的「技能树」:每一代都在某几个维度上点满或重构,而这份讲义,就是要帮你把这棵技能树从根到叶都看清楚。
2 二、基础补课:从「只会看文字的大脑」到「会看世界的大脑」
2 二、基础补课:从「只会看文字的大脑」到「会看世界的大脑」
在正式拆解 Qwen-VL 之前,我们需要先达成一些共识。
很多同学觉得多模态(Multimodal)很难,是因为它横跨了 CV(计算机视觉)和 NLP(自然语言处理)两个领域。CV 的人习惯看像素、卷积和 IoU;NLP 的人习惯看 Token、Attention
和 Perplexity。
但实际上,它们在数学本质上是完全相通的。
这一节,我们将用“李宏毅式”的直觉,快速过一遍三个最核心的基础概念:ViT(视觉的语言化)、RoPE(位置的旋转编码)、Cross-Attention(模态间的桥梁)。这三个概念是理解后续所有
Qwen-VL 骚操作(如 M-RoPE, DeepStack)的地基。
2.1 视觉的语言化:ViT (Vision Transformer)
2.1 视觉的语言化:ViT (Vision Transformer)
如果我们要让 LLM 看懂图片,第一步必须是把图片变成 LLM 能理解的形式。LLM 能理解什么?它只能理解 Sequence (序列)。
所以,ViT 做的事情只有一件:把一张二维的图片,切碎成一串一维的向量序列。
🎨 图解:从 Pixel 到 Patch Embedding
💡 为什么要切块 (Patching)?
如果把每个像素都当成一个 token,一张 224x224 的图就有 50,176 个 token,Attention 计算量直接爆炸($O(N^2)$)。
切成 16x16 的 patch 后,只有 $14 \times 14 = 196$ 个
token,这就在计算效率和信息保留之间找到了平衡。
⚠️ Qwen-VL 的伏笔
标准的 ViT 需要固定分辨率(比如 224 或 336)。
思考题: 如果来了一张长条形的手机截图(1080x2400)怎么办?强行缩放会变形,补零(Padding)会浪费算力。这个问题正是
Qwen2-VL Dynamic Resolution 要解决的核心痛点。
2.2 优雅的位置编码:RoPE (Rotary Positional Embedding)
2.2 优雅的位置编码:RoPE (Rotary Positional Embedding)
Transformer 的 Attention 机制本质上是“位置无关”的(Permutation Invariant)。如果你打乱句子的顺序,Attention
算出来的关联度是一样的。所以我们必须告诉模型:“谁在谁的前面”。
RoPE 是目前最优雅的解决方案。它不是把位置向量加(Add)上去,而是把词向量在空间中旋转(Rotate)一个角度。
RoPE 的几何直觉:相对距离 = 旋转角度差
为什么 RoPE 对 Qwen-VL 这么重要?
因为 Qwen-VL 系列需要处理的不仅仅是一维文本,还有二维图像和三维视频。
在 Qwen2-VL 中,为了统一这些模态,作者提出了 M-RoPE (Multimodal RoPE):把旋转推广到了 3D 空间(时间、高度、宽度)。如果你不理解
RoPE 的“相对位置由旋转角度决定”这个核心直觉,你就无法理解 M-RoPE 是如何在三个维度上“解耦”位置信息的。
2.3 模态的桥梁:Cross-Attention
2.3 模态的桥梁:Cross-Attention
这是 Qwen-VL 将视觉特征融入 LLM 的关键机制。在 Self-Attention 中,Query, Key, Value 都来自同一个序列。但在 Cross-Attention 中,它们分家了。
💊 抓药的比喻
想象 LLM 是一个老中医,Vision Encoder 是一个巨大的中药柜。
- Query (Q): 老中医手里的“药方”(当前文本上下文需要什么信息?比如“图里的猫在哪?”)。
- Key (K): 药柜上每个抽屉的“标签”(图片的纹理、形状、位置特征)。
- Value (V): 抽屉里实际的“药材”(具体的视觉特征向量)。
Cross-Attention 就是老中医拿着药方 (Q),去匹配药柜上的标签 (K),然后取出对应的药材 (V),融合到当前的诊断(文本生成)中。
注意:
Qwen-VL 在第一代使用了类似的机制(Adapter),但在后续版本(Qwen2-VL)中为了效率,改成了更直接的 MLP Merger(C-Former 变体)。了解 Cross-Attention 是为了理解“为什么我们要把视觉特征映射到语言空间”。
2.4 坐标的离散化:把“画框”变成“说话”
2.4 坐标的离散化:把“画框”变成“说话”
Qwen-VL 不仅能看图,还能在图上把物体框出来(Grounding)。
很多同学直觉上会认为:这肯定是用回归(Regression)做的吧?预测 x, y 的连续数值?
错!大错特错!
LLM 的世界里只有 Token。为了让 LLM 能输出坐标,我们必须把连续的像素坐标,强制变成离散的字典词。
🎯 图解:Binning —— 将世界网格化
Qwen-VL 的做法:
- 在词表中新增 1000 个特殊 token:
<0>,<1>, ...<999>。 - 把图片的长宽归一化到 [0, 1000]。
- 当模型需要输出坐标时,它实际上是在做1000 分类的选择题。
答:切太少(100),定位精度不够,框不准;切太多(10000),词表会爆炸,而且分类头(Classification Head)会变得极其难训练(类别太多了)。1000 是一个经验上的 Sweet Spot。
2.5 掩码的艺术:Causal vs. Bidirectional Mask
2.5 掩码的艺术:Causal vs. Bidirectional Mask
最后一个关键点:时间与空间在 Attention 里的区别。
LLM(GPT 类)是单向的(Causal),因为你不能在说第一个字的时候就看到第十个字(那是作弊)。
但是,看图是双向的(Bidirectional)!你看一张照片,是左眼看右眼,还是右眼看左眼?是一眼全看到的!图片里的像素之间没有“先后顺序”。
冲突来了: 当我们把“双向的图片 Token”塞进“单向的 LLM”里时,Attention Mask 该怎么画?
混合 Attention Mask 矩阵
关键规则:
- Image 内部 (左上角): 全 1 矩阵。图片的所有 Patch 可以互相看见,因为它们是同时存在的空间信息。
- Text 内部 (右下角): 下三角矩阵。文本必须遵守因果律,第 $t$ 个字只能看 $1 \dots t-1$。
- Text 看 Image (左下角): 全 1。无论说到哪句话,都可以回头去看完整的图片。
- Image 看 Text (右上角): 全 0。图片存在时,后续的文字还没生成呢,当然不能看(防止泄漏)。
这个特殊的 Mask 设计,是 Qwen-VL 这类 Decoder-only 模型能同时处理理解(Understanding)和生成(Generation)任务的底层逻辑保障。
3 三、Qwen 家族谱系:从 Qwen-LM 到 Qwen3-VL
3 三、Qwen 家族谱系:从 Qwen-LM 到 Qwen3-VL
接下来我们先从宏观视角看一眼:Qwen 家族到底长成什么样?哪些是「只会文字的兄弟姐妹」,哪些是「视觉版」、哪些是「专攻图片」、哪些又是「主打长上下文和推理」?
最早的是 Qwen-LM 家族,负责打好纯文本世界的地基;在这个地基上,Qwen-VL 把「看图」的能力接上来;然后 Qwen2 系列进一步在语言和视觉上双向升级,衍生出 Qwen2-VL;之后是强调更强推理和更长上下文的 Qwen2.5 及 Qwen2.5-VL;最后是把一切整合到 256K 上下文 + 强思考能力上的 Qwen3-VL。
我们用一幅 Mermaid 图把这一系列的演化用「版本进化树」的方式画出来。
图解:Qwen 家族进化树 (The Phylogeny Tree)
核心事实:视觉语言模型不是一个独立物种,而是长在语言大模型这棵树上的一条分支。如果底层语言模型升级了,视觉版本也要跟着重做一遍,而且往往会顺带引入新的训练策略和新的视觉模块设计。
因此,要理解 Qwen-VL 这一支,你心里最好先有一个「Qwen 纯文本发展史」的隐形时间轴:每一次文本 backbone 的升级(从 Qwen 到 Qwen2,再到 Qwen2.5 和 Qwen3),都会为视觉版本带来新的上下文长度、更好的对齐能力和更强的推理能力。
3.1 第一代:Qwen-VL
在 Qwen-LM 的基础上,通过精心设计的视觉 receptor、输入输出接口,让模型第一次可以稳定地做「看图说话 + 定位 + 读文字」。这一代的重点是把所有 基础视觉能力 补全。
3.2 第二代:Qwen2-VL
关键词:Dynamic Resolution 和 M-RoPE。不再被固定分辨率限制,也不想把视频当成无关图片堆叠。它在文档、UI、长视频任务上有了明显优势。
3.3 第三代:Qwen2.5-VL
角色是「打磨内功」。进一步加强了数学推理、代码理解和结构化抽取(JSON、表格)的能力,同时拉长了上下文长度,让模型在处理长文档时更稳。
3.4 第四代:Qwen3-VL
256K 上下文 + DeepStack + 思考模式。彻底重构了「长上下文 + 多模态 + 推理」的关系。视觉信息多层注入,支持 thinking 模式,对标顶尖闭源模型。
接下来几节,我们会按照「版本迭代式讲解」的方式,分别把四代 Qwen-VL 拆成:模型结构、损失设计、训练流程和典型能力四个模块来讲,让你可以清楚感受到每一代在「V1 naive 方案」的基础上是如何一步一步升级的。
4 四、第一站:Qwen-VL —— 给大脑装上“义眼”的艺术
4 四、第一站:Qwen-VL —— 给大脑装上“义眼”的艺术
各位同学,欢迎来到 Qwen-VL 的世界。如果我们把纯文本模型(Qwen-7B)比作一个博学但双目失明的智者,那么 Qwen-VL 这个项目要做的事情,就是给他做一台精密的手术:装上一双“义眼”。
但这手术没那么简单!你不能直接把视神经接到语言中枢上,因为它们说的“语言”完全不通——视觉神经传的是像素信号(Pixel),语言中枢要的是语义符号(Token)。
Qwen-VL 的核心贡献,就在于设计了一个绝妙的“翻译器”(Adapter)和一套严谨的“康复训练流程”(3-Stage Training),让这两个本来老死不相往来的模块,学会了协同工作。
4.1 架构拆解:三大件的选择哲学
4.1 架构拆解:三大件的选择哲学
这也是李老师经常强调的 Step 1: Define a Function Set。Qwen-VL 的网络结构非常经典,它由三个核心组件构成。这看起来像是“搭积木”,但每一块积木的选择都大有讲究(SOTA Selection)。
Qwen-7B
LLM Backbone
这是基座。为什么选 Qwen-7B?因为在当时(2023年),它在同尺寸模型中表现优异。注意:在第一阶段训练时,它是被冻结(Frozen)的,像个高傲的教授,不肯轻易改变自己的参数。
ViT-bigG
OpenCLIP Init
参数量高达 1.9B!这是一个巨型视觉编码器。它负责把 448×448 的高分辨率图像切成小块(Patch),变成一串密集的特征向量。它也是先冻结,后解冻。
VL Adapter
Position-aware C-Attn
这就是那个“翻译器”。不同于 LLaVA 简单暴力的 Linear Projection,Qwen-VL 用了一个单层的 Cross-Attention 模块,把视觉特征“压缩”成固定长度(256)。
🔍 显微镜视角:Qwen-VL 的数据流 (Data Flow)
🎓 李老师的画外音:为什么要用 Attention 做压缩?
大家想一想,如果我们只是用一个全连接层(Linear)或者池化层(Pooling),是不是太“死板”了? Cross-Attention 的好处在于“查询”(Query)机制。 我们设定 256 个可学习的 Query 向量,你可以把它们想象成 256 个“探针”。在训练过程中,这些探针学会了去图像特征里“寻找”不同的信息——有的探针专门找纹理,有的找形状,有的找位置。 这就是为什么 Qwen-VL 能够在保持 token 数量极少(256个)的情况下,依然保留丰富的视觉细节。
4.2 训练三部曲:像教学生一样教模型
4.2 训练三部曲:像教学生一样教模型
Qwen-VL 的训练过程非常经典,堪称多模态训练的教科书。它采用了三阶段训练法(3-Stage Training Pipeline)。这其实很像我们教人类学生:先学认字,再学做题,最后学礼貌对话。
Stage 1: Pre-training (预训练) —— “视觉对齐”
任务: 让模型把图片和简单的描述(Caption)对应起来。
状态:
- Vision Encoder: Frozen (不更新)
- Adapter: Learnable (更新)
- LLM: Frozen (不更新)
"这时候大脑(LLM)和眼睛(ViT)都是锁住的,只有中间的翻译官(Adapter)在拼命学习如何把眼睛看到的信号翻译成大脑能听懂的语言。"
Stage 2: Multi-task Pre-training (多任务预训练) —— “解锁大脑”
任务: 引入更高分辨率的输入(448x448),训练更难的任务,比如“框出图中的猫”、“念出图里的字”。
状态:
- Vision Encoder: Learnable (终于解冻了!)
- Adapter: Learnable
- LLM: Learnable (大脑开始适应视觉信号)
"这一步是质变。我们把全模型都解冻了(Full Fine-tuning)。为什么要解冻?因为光靠翻译官不够了,大脑自己也得学会处理新的视觉知识,尤其是为了适应更高的分辨率和更细粒度的任务(如 Grounding)。"
Stage 3: Supervised Fine-tuning (SFT) —— “学会聊天”
任务: 用对话格式的数据(ChatML),教模型怎么像个助手一样说话,而不是只会冷冰冰地输出标签。
状态:
- Vision Encoder: Frozen (通常为了稳定)
- Adapter: Learnable
- LLM: Learnable
4.3 核心黑科技:如何让模型“指哪打哪”?(Grounding)
4.3 核心黑科技:如何让模型“指哪打哪”?(Grounding)
大家可能注意到了,Qwen-VL 最惊艳的能力之一是 Visual Grounding(视觉定位)。你问它“狗在哪里?”,它不仅能说“在草地上”,还能给你画一个框
[x1, y1, x2, y2]。它是怎么做到的?
🔴 传统方法的痛点
传统的 LLM 词表里根本没有坐标的概念。如果我们直接输出数字 "256, 334...",这会被切分成好几个 token,模型很难理解这几个 token 代表一个连续的 2D 空间位置。
🟢 Qwen-VL 的对策
位置归一化 + 特殊 Token。
1. 将所有坐标归一化到 [0, 1000) 区间。
2. 引入两个特殊符号 <box> 和 </box>。
3. 训练数据长这样:Describe the dog <ref>the dog</ref><box>(200,200),(500,600)</box>
这种设计极其聪明。它把“检测任务”变成了一个“语言生成任务”。对于 LLM 来说,输出 (200,200) 和输出一个单词没有任何本质区别。这就是 Next Token
Prediction 统一万物的魅力!
小结: Qwen-VL 证明了只要有好的适配器(Adapter)和分阶段的训练策略,即便只有 7B 的语言模型,也能拥有 SOTA 级别的视觉理解能力。但它还有个遗憾——分辨率是固定的(448x448),这导致看长图或细长文档时会变形。这个问题,将在下一章 Qwen2-VL 中得到革命性的解决。
5 五、第二站:Qwen2-VL —— 打破分辨率的“削足适履”
5 五、第二站:Qwen2-VL —— 打破分辨率的“削足适履”
🤔 课堂提问:Qwen-VL 的“近视眼”是怎么来的?
🤔 课堂提问:Qwen-VL 的“近视眼”是怎么来的?
同学们,还记得我们在上一章讲的 Qwen-VL 吗?它虽然是个优秀的“看图说话”选手,但它有一个致命的弱点——“近视眼”。
不管你给它一张长条形的长微博截图,还是一个宽屏的 IMAX 电影海报,它都会粗暴地把图片 Resize 成 448×448 的正方形。
后果很严重:
- 细节丢失: 很多细小的文字在缩小后直接变成了噪点。
- 比例失真: 瘦高的人变成了矮胖子,圆变成了椭圆,模型的世界观被扭曲了。
- 算力浪费: 如果是一张很小的 256x256 的图,为了凑 448,还得强行放大或者 Padding,浪费了宝贵的计算资源。
Qwen2-VL 的使命,就是彻底解决这个问题。 它引入了两大杀手锏,听起来很学术,但本质上非常直觉:
Naive
Dynamic Resolution (动态分辨率)
+
M-RoPE
(多模态旋转位置编码)。
5.1 动态分辨率 (Naive Dynamic Resolution):像玩俄罗斯方块一样处理图片
5.1 动态分辨率 (Naive Dynamic Resolution):像玩俄罗斯方块一样处理图片
这一代模型最核心的改变是:我们不再强制 Resize 图片了! 或者更准确地说,我们不再把图片 Resize 成一个固定的正方形。
但是,Transformer 本质上还是需要一个序列(Sequence)。如果图片大小不一,Token 数量就不一样,怎么把它们塞进同一个 Batch 里训练呢?Qwen2-VL 并没有发明什么极其复杂的数学变换,而是想出了一个非常工程化、非常实用的办法,我们称之为“动态切块法”。
Step 1: 这里的 "Naive" 是什么意思?
它指的是一种最朴素的策略:我们依然会对图片做 Resize,但目标不再是固定的 $H \times W$,而是最接近原始分辨率的 $14 \times 14$ 的倍数。
Target: (14*N) x (14*M)
Result: 98x196 (最接近)
Step 2: 2x2 Pooling (特征压缩)
为了进一步减少 Token 数量,ViT 输出的 Patch 特征(14x14)会被做一个 2x2 Pooling。这意味着,最终进入 LLM 的每一个 Visual Token,实际上代表了原图上 28x28 的像素区域。
🎨 深度图解:从“任意图片”到“Token流”的完整变形记
1 什么是 "Naive"?
这里的 Naive
是一种自谦。它指的不是算法幼稚,而是策略上的朴素:我们不搞复杂的物体检测裁剪(Crop),也不搞多尺度金字塔,就是最简单的:
Resize 到最近的 14 倍数 -> 切 Patch ->
进 ViT。
这种简单性保证了训练的稳定性,也让工程实现(FlashAttention VarLen)变得可能。
2 2x2 Pooling 的妙处
为什么要最后做一次 2x2 Pooling?
因为 ViT 的 Patch Size 是 14x14,对于高分辨率图片,Token 数量会爆炸(448x448 就有 1024 个 token)。
2x2 Pooling 相当于把特征图的尺寸缩小了一半(分辨率变成 28x28),Token 数量直接减少了 75%!这大大减轻了 LLM
的负担,同时保留了足够的视觉语义。
5.2 M-RoPE:给 Token 装上“三维 GPS”
5.2 M-RoPE:给 Token 装上“三维 GPS”
解决了分辨率问题,我们迎来了一个更棘手的问题:位置感(Positional Awareness)的丢失。
在传统的纯文本 LLM 中,位置是一维的(第1个字,第2个字...)。这很简单,用 RoPE 就能完美解决。
但在 Qwen2-VL 中,视觉 Token 是被“压扁”后送进来的。如果把一张 2D 图片压成 1D 序列,原本上下的邻居关系就彻底乱套了。更别提视频了,那是 3D 的(时间+空间),压扁后更是灾难。
🧭 M-RoPE 的核心思想:三维位置解耦
Qwen2-VL 的 M-RoPE (Multimodal Rotary Positional Embedding) 采用了一种极具几何美感的做法:它没有引入额外的 Embedding 层,而是直接操作旋转矩阵。它把 Token 的 Embedding 向量切成三段,分别由三个独立的旋转矩阵控制,对应时间、高度和宽度。
📊 论文原图 Figure 3 深度解析
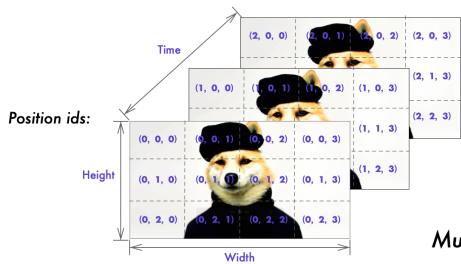
这张图(Figure 3)是理解 M-RoPE 的钥匙。它展示了不同模态下,这三个分量是如何“退化”或“激活”的:
-
📄
Text (纯文本) 文本是一维的线性流。所以在文本部分,我们让 Temporal, Height, Width 的 ID 完全相同(都是序列索引 $i$)。这使得 M-RoPE 退化为普通的 1D RoPE,兼容了预训练的语言模型能力。
-
🖼️
Image (图片) 图片是静止的 2D 平面。因此,Temporal ID 被冻结为常数(比如 0),而 Height 和 Width ID 则随着像素网格扫描而变化。这样,模型就能感知到二维空间结构。
-
🎬
Video (视频) 视频是多张图片的堆叠。这里三个维度火力全开:Temporal ID 表示帧号(Frame 1, Frame 2...),Frame 内部依然保持 H/W 的 2D 变化。模型因此拥有了完整的 3D 时空感知能力。
5.X 进阶思考:Adapter 的“逆向进化”之谜
5.X 进阶思考:Adapter 的“逆向进化”之谜
🤔 李老师的小黑板:为什么要“退步”?
细心的同学可能发现了:
Qwen-VL (v1) 用的是 Cross-Attention (256
Queries),这看起来很高级,能把图片压缩得很短。
Qwen2-VL (v2) 却改回了简单的 2x2 Pooling +
MLP,这看起来像是技术的“退步”。
为什么?
Cross-Attention 的代价
Query 是这一组可学习的向量。它们像一群“探针”,在图片特征里到处乱跑。
缺点: 它们会打乱空间拓扑结构!虽然位置编码还在,但那种“像素 A 在像素 B
左边”的物理直觉变弱了。这对于需要精确坐标定位 (Grounding) 的任务非常不利。
MLP Merger 的回归
2x2 Pooling 是一种硬连接。它强制 Token保留原始的 2D 空间结构。
优点: 虽然 Token 变多了(压缩率低),但它完美保留了“我在哪”的空间信息。这正是
Qwen2-VL 在文档解析和 UI 操作上大杀四方的秘密。
"有时候,保留原始的物理结构比提取抽象的语义更重要。—— Qwen2-VL 的设计哲学"
5.3 家族新成员:2B / 7B / 72B —— 从端侧到云端
5.3 家族新成员:2B / 7B / 72B —— 从端侧到云端
Qwen2-VL 不再是单兵作战,而是推出了三个不同量级的模型,覆盖了从手机端侧到云端超算的全部场景。这里有一个非常有意思的设计细节:无论 LLM 有多大,它们都共享同一个 600M 参数量的视觉编码器(ViT)!
这意味着,哪怕是最小的 2B 模型,它的“眼睛”也是和 72B 模型一样锐利的,只是“大脑”处理信息的能力不同。
Qwen2-VL-2B
Edge / Mobile
- ✓ 可以在手机上流畅运行
- ✓ 文档扫描、实时翻译
- ✓ 视觉感知能力不缩水
Qwen2-VL-7B
Consumer GPU
- ✓ 性价比之王
- ✓ 单卡 RTX 3090/4090 可跑
- ✓ 大多数 Demo/应用的首选
Qwen2-VL-72B
SOTA Killer
- ✓ 对标 GPT-4V 闭源模型
- ✓ 复杂长视频分析
- ✓ Agent 规划与决策
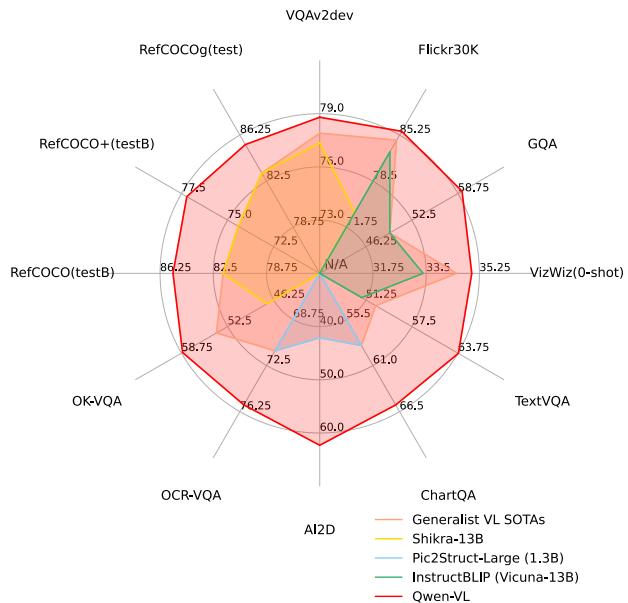
🌟 全能表现 (Capabilities Overview)
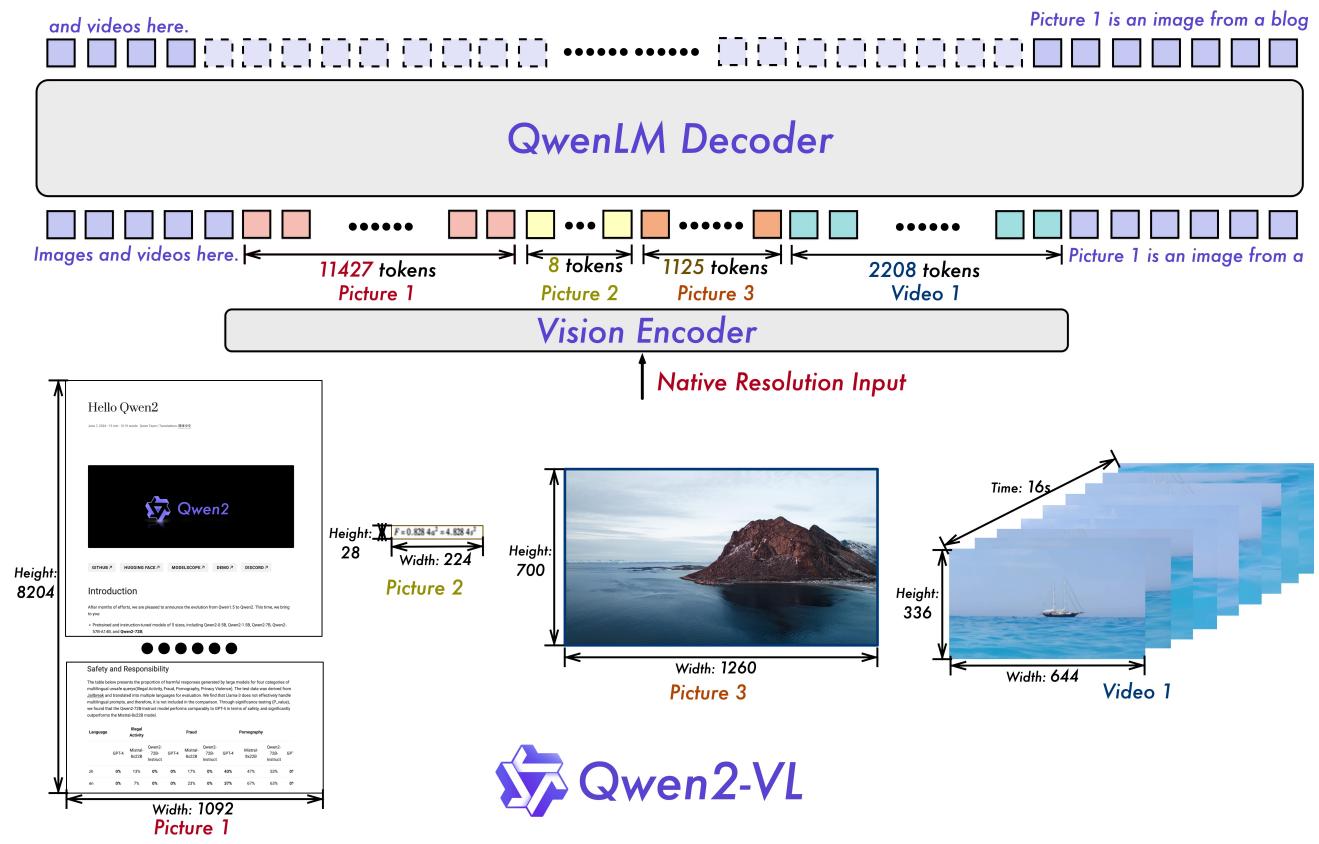
Figure 2: Qwen2-VL 的能力全景图。无论是识别植物种类、理解视频中的复杂剧情,还是解决高难度的数学几何题,亦或是多语言 OCR,它都表现得游刃有余。
本章小结
Qwen2-VL 通过 Naive Dynamic Resolution 治好了“近视眼”,通过 M-RoPE 治好了“方向盲”。它就像一个视力矫正成功、戴上了 3D 眼镜、智商还在线的超级助手。
但是,故事还没有结束。面对特别复杂的文档(如密密麻麻的发票、报表),或者需要极强逻辑推理能力的场景,它有时候还是会“眼高手低”。下一站,我们将迎来 Qwen2.5-VL,看看它是如何进一步打磨细节,成为真正的“文档专家”的。
6 六、第三站:Qwen2.5-VL —— 从“能看”到“精通”的细节狂魔
6 六、第三站:Qwen2.5-VL —— 从“能看”到“精通”的细节狂魔
🥪 为什么我们需要 Qwen2.5-VL?
🥪 为什么我们需要 Qwen2.5-VL?
如果说 Qwen2-VL 解决了“能不能看清不同形状图片”的问题,那么 Qwen2.5-VL 要解决的就是“能不能看懂最复杂的细节”。
在技术报告中,作者用了一个非常形象的比喻:目前的多模态模型就像是一块“夹心饼干的中间层”——虽然能做很多任务,但离顶尖水平(夹心饼干的上下两层美味)还差一口气。
这“一口气”差在哪里?
- 文档解析: 密密麻麻的表格、乐谱、化学分子式,以前的模型一看就晕。
- 精准定位: 不只是画个框,而是要精确到像素点(Point)甚至计数(Counting)。
- 时间感知: 视频不是匀速播放的幻灯片,快进、慢放、长达一小时的视频,怎么定位到第 59 分 30 秒的那个瞬间?
为了填补这最后一块拼图,Qwen2.5-VL 祭出了四大杀招: Native Dynamic ViT Window Attention Absolute Time M-RoPE 以及 4.1T Tokens Data。
6.1 架构总览:更原生,更懂时间
6.1 架构总览:更原生,更懂时间
首先,让我们看一眼 Qwen2.5-VL 的全身照(Figure 1)。如果你仔细对比上一代,会发现结构类似,但内核已经换了。
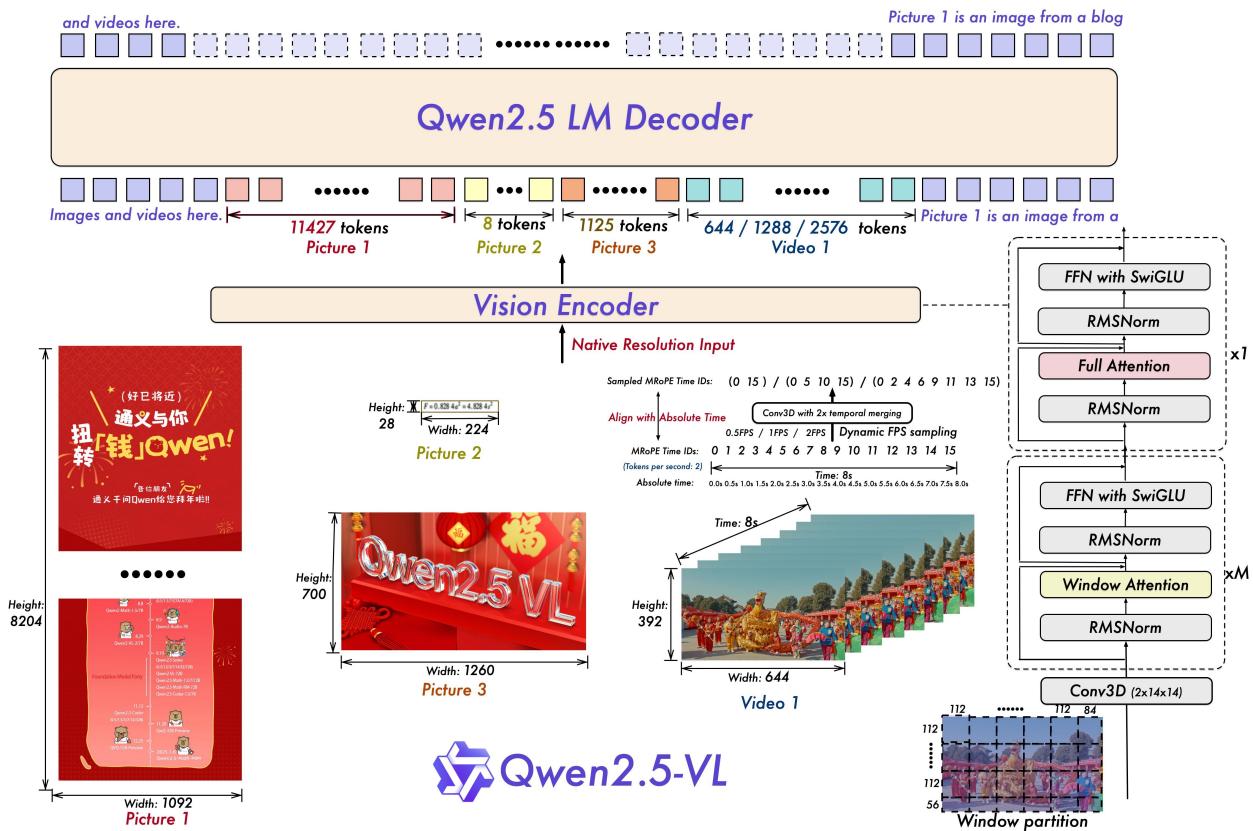
Figure 1: Qwen2.5-VL 架构图。注意中间醒目的 "Native Resolution Input" 和 "Align with Absolute Time"。
🖼️ Spatial: Native Dynamic ViT
不再是简单的“切片+Reszie”。Qwen2.5-VL 从零开始训练了一个原生支持动态分辨率的 Vision Transformer。它引入了 Window Attention,让计算复杂度从 $O(N^2)$ 降下来,从而轻松吞下 4K 甚至更高清的图。
⏱️ Temporal: Absolute Time M-RoPE
不再只是数“第几帧”。Qwen2.5-VL 将 M-RoPE 的时间维度与绝对物理时间(秒)对齐。哪怕视频忽快忽慢(Dynamic FPS),模型也能知道现在是“第 30 秒”而不是简单的“第 150 帧”。
6.2 Native Dynamic Resolution:从 Naive 到 Native 的进化
6.2 Native Dynamic Resolution:从 Naive 到 Native 的进化
同学们,Qwen2-VL 叫 Naive Dynamic Resolution,Qwen2.5-VL 叫 Native Dynamic Resolution。这一字之差,差在哪里?
Naive vs. Native: 视觉处理的进化
🔴 Naive (Qwen2-VL)
利用现成的 ViT(通常是训练在固定分辨率上的),强行把不同比例的图切成 Patch 喂进去。
痛点: 如果图片太大(比如长文档),Token 数量爆炸,全局 Attention 计算量直接炸穿显存。
🟢 Native (Qwen2.5-VL)
从零训练一个 ViT,天生习惯变长输入。并在内部引入 Window Attention。
优势: 把图片切成若干个 112x112 的窗口。大部分层只看窗口内,只有少数层看全局。算力开销大幅降低!
🪟 图解:Window Attention 如何拯救显存
6.3 绝对时间编码:解决“变速运动”的难题
6.3 绝对时间编码:解决“变速运动”的难题
Qwen2-VL 使用 M-RoPE 引入了 Temporal ID,这是一个巨大的进步。但是,旧的 Temporal ID 是基于帧序号(Index)的:第 1 帧、第 2 帧...
这有什么问题? 现实中的视频采样率(FPS)是会变的!
场景 A: 1 秒抽 1 帧。第 5 帧代表第 5 秒。
场景 B: 1 秒抽 5 帧。第 5 帧代表第 1 秒。
如果模型只知道“这是第 5 帧”,它根本不知道这代表多长的时间跨度。
⏱️ 图解:Relative Index vs. Absolute Time
Qwen2.5-VL 将 Temporal ID 直接与绝对时间(秒)挂钩。通过这种方式,模型不仅能理解“先后顺序”,还能感知“节奏快慢”。这对于理解长视频(比如长达一小时的电影)至关重要。
6.4 数据工程:不仅仅是“多”,而是“精”
6.4 数据工程:不仅仅是“多”,而是“精”
模型架构只是骨架,数据才是灵魂。Qwen2.5-VL 的预训练数据量达到了惊人的 4.1 Trillion Tokens(是 Qwen2-VL 的 3 倍多)。
但这里更值得关注的是它是如何构建那些特殊能力数据的。
📄 Document Omni-Parsing
为了让模型成为“全能读文档专家”,Qwen 团队合成了一大批HTML 格式的文档数据。
# paragraph
<p bbox="x1 y1 x2 y2"> content </p>
# table
<table bbox="..."> ... </table>
...
Key Innovation: 所有的内容(文字、表格、公式)都带上了 Bounding Box。模型不仅学会了认字,还学会了 Layout(排版布局)。
🎯 Absolute Grounding
为了支持高精度定位,Qwen2.5-VL 使用了绝对坐标(基于原始分辨率),而不是之前的归一化坐标(0-1000)。
数据来源非常硬核:
- PixMo (Pointing & Counting)
- Synthetic Data from Grounding DINO & SAM
- Oven-Vocabulary Detection Data
6.5 实力展示:DocVQA 与 Agent 能力的飞跃
6.5 实力展示:DocVQA 与 Agent 能力的飞跃
在 Qwen2.5-VL 的技术报告中,最亮眼的成绩单莫过于 Document Understanding 和 Agent 能力。
🏆 DocVQA & InfoVQA 成绩单
| Model | DocVQA (test) | InfoVQA (test) | ChartQA (test) |
|---|---|---|---|
| GPT-4o | 91.1 | 80.7 | 86.7 |
| Claude 3.5 Sonnet | 95.2 | 74.3 | 90.8 |
| Qwen2.5-VL-72B | 96.4 👑 | 87.3 👑 | 89.5 |
* 数据来源:Technical Report Table 5
在 DocVQA 上,Qwen2.5-VL-72B 达到了 96.4 的恐怖分数,这说明它在处理文档细节时已经超越了大多数闭源模型。
此外,在 Agent 相关的 Benchmark(如 Android World, OSWorld)上,Qwen2.5-VL 也展现出了惊人的决策能力。这得益于它在训练数据中引入了大量 GUI 截图和操作序列(Action Traces)。
本章小结
Qwen2.5-VL 是 Qwen-VL 家族的一次“精细化”革命。
它用 Native Dynamic Resolution + Window Attention 解决了超高分辨率下的计算效率问题;
它用 Absolute Time M-RoPE 解决了长视频的时间感知问题;
它用 DocOmni Data 解决了复杂文档的结构化理解问题。
到这里,我们在感知层面似乎已经做到极致了。但是,如果我们要处理几十万 Token 的超长上下文,或者进行复杂的逻辑推理(Thinking
Mode),现有的架构还够用吗?
下一站,终极形态 —— Qwen3-VL 登场。
6 第四站:Qwen3-VL 终极形态:256K 上下文与 DeepStack 的降维打击
6
第四站:Qwen3-VL
终极形态:256K 上下文与 DeepStack 的降维打击
🚀 从“能看懂”到“能思考”的跨越
🚀 从“能看懂”到“能思考”的跨越
同学们,如果我们把 Qwen2.5-VL 比作一位眼神犀利、明察秋毫的“文档专家”,那么 Qwen3-VL 就是一位拥有无限记忆且深思熟虑的“智者”。
到了这一代,Qwen 团队不再满足于“看清”一张图或几秒视频,而是向着多模态领域的三个“圣杯”发起了冲击:
原生 256K 上下文
不再是简单的 RoPE 延展,而是从训练开始就让模型习惯“吞噬”整本书、整部电影。视觉与文本在这个尺度上实现了真正的自由交织。
System 2 Thinking
引入了类似 OpenAI o1 的“慢思考”模式。面对复杂的几何题或推理任务,模型会先生成长长的思维链(CoT),再给出答案。
DeepStack 架构
打破了“视觉仅在输入层注入”的传统,构建了直通深层的“视觉高速公路”。这是大模型架构的一次重要微创新。
7.1 架构革新:DeepStack 与视觉信号的“渗透”
7.1 架构革新:DeepStack 与视觉信号的“渗透”
让我们先看这张极其重要的架构图(Figure 1)。请大家把注意力集中在最右侧那个看似复杂的连接结构上——那就是 DeepStack。
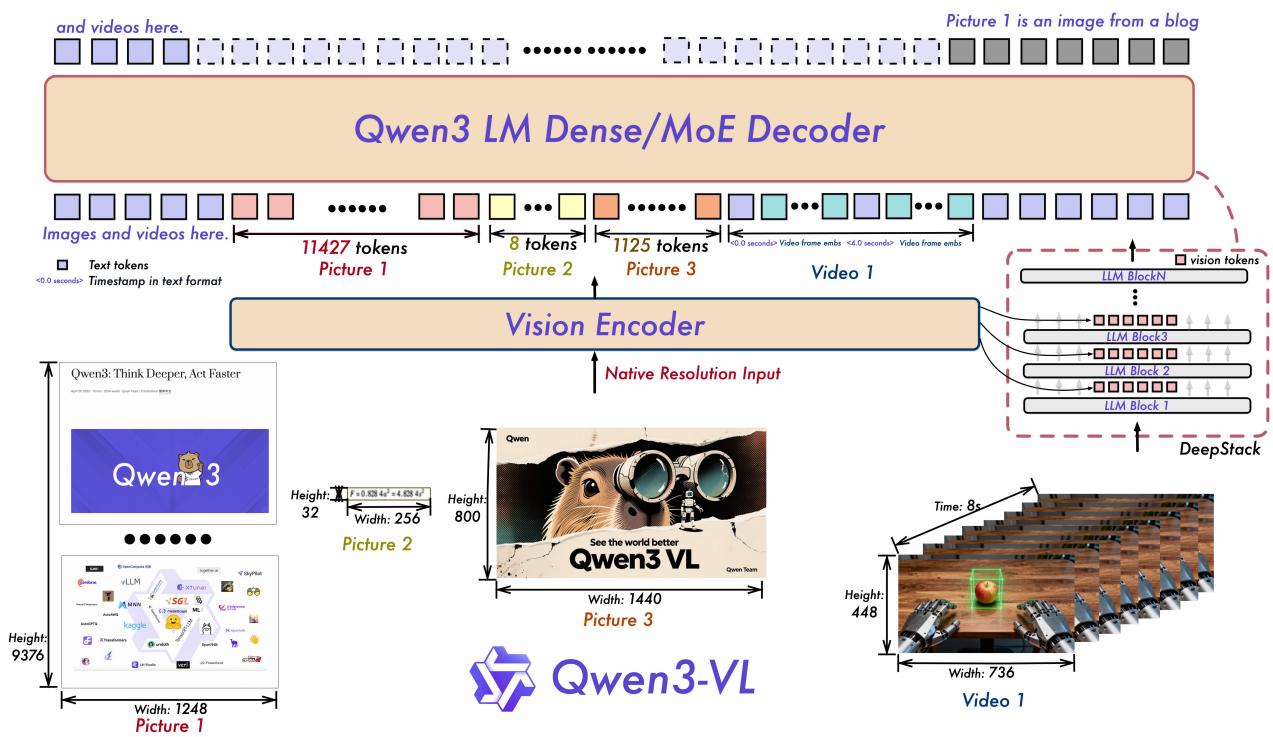
Figure 1: Qwen3-VL 架构全景。注意右侧的虚线框部分,视觉特征不再是一次性买卖,而是被分层注入到了 LLM 的不同深度。
为什么需要 DeepStack?(The Vanishing Vision Problem)
传统的 LVLM(如 LLaVA、Qwen-VL v1/v2)通常采用 "Early Fusion" 策略:视觉 Token 和文本 Token 拼接后,一起送入 LLM 的第一层。
但是,随着 LLM 越来越深(Qwen2.5-72B 有 80 层!),底层的视觉信号在经过几十层的 Self-Attention 和 FFN 变换后,会被“语言模式”逐渐稀释甚至淹没。这就好比你小学一年级看了一张图,让你在读完 80 年书之后的博士论文里描述这张图的细节,你早就忘光了。
DeepStack 的解法: 既然怕忘,那就“多看几眼”。
🏗️ 深度图解:DeepStack 的“梯度高速公路”
🎯 解决的问题
- 信息遗忘: 确保 LLM 的深层(负责复杂推理)能直接访问到原始的视觉特征,而不是仅依赖前面层传过来的“二手信息”。
- 梯度消失: 在训练时,梯度可以通过这些横向连接(Shortcut)直接回传到 Vision Encoder,加速收敛。
⚡ 设计巧思
注意,DeepStack 是把视觉 Token 相加 (Add) 到 LLM 的 Hidden States 上,或者是作为 Cross-Attention 的 Key/Value 注入(具体取决于实现,Qwen3-VL 采用的是 Residual Connection 方式)。这意味它没有增加 LLM 的 Context Length!在推理时,这几乎是免费的性能提升。
7.2 Interleaved MRoPE:频谱再平衡
7.2 Interleaved MRoPE:频谱再平衡
Qwen2-VL 的 M-RoPE 已经很强了,但在超长视频理解中暴露出了一个隐蔽的缺陷:频谱失衡 (Spectral Imbalance)。
🧐 什么是频谱失衡?
RoPE 的特性是:Embedding 向量的前几维对应高频旋转(关注局部位置),后几维对应低频旋转(关注全局长距离)。
在 Qwen2-VL 中,我们是这样切分向量的:[时间 T | 高度 H | 宽度 W]。
这意味着:时间信息 T 总是占据高频段,而空间信息 W 总是占据低频段。
结果就是:模型对“局部时间变化”很敏感,但对“长跨度的时间依赖”感知较弱(因为低频段被 H 和 W 占了)。这对长视频理解非常不利。
🌊 图解:Interleaved MRoPE 的“编织”艺术
7.3 视频时间戳的回归:Text-based Time Alignment
7.3 视频时间戳的回归:Text-based Time Alignment
Qwen2.5-VL 在视频处理上还有一个重大改动:放弃纯粹的 Absolute Position ID,回归 Text-based Timestamp。
Absolute Pos ID (Old)
把第 $t$ 秒直接映射到一个很大的 Position ID(比如 ID=30000)。
问题:超长视频会导致 ID 溢出 RoPE 的外推极限;而且对变帧率(Variable FPS)非常敏感。
Explicit Text Timestamp (New)
直接在视觉 Token 序列里插入文字形式的时间戳。
优势:把“时间感知”变成“文本阅读”任务。模型只需要读懂 <00:05> 这个字符串,就能知道现在是第几秒,而不受 ID 大小限制。
7.4 Post-training:Thinking Mode 的诞生
7.4 Post-training:Thinking Mode 的诞生
Qwen3-VL 的后训练(Post-training)阶段引入了一个激动人心的特性:System 2 Thinking (慢思考模式)。这明显是受到了 OpenAI o1 的启发,但在多模态领域,这意味着什么?
Thinking Process in VLM
视觉信息提取 (Perception)
"我看到图中有一个红色的三角形和一个蓝色的正方形,它们部分重叠..."
逻辑推演 (Reasoning)
"题目问重叠面积。首先我需要根据坐标计算三角形的方程,然后..."
自我反思 (Reflection)
"等等,我刚才看错了,那个不是正方形,是个长方形。我需要重新计算..."
最终回答 (Conclusion)
"重叠面积是 5.5 平方厘米。"
Qwen3-VL 提供了 Thinking 和 Non-thinking 两个版本。
对于简单的 OCR 或描述任务,Non-thinking 版响应快、成本低。
对于复杂的数学几何题或长视频推理,Thinking 版虽然慢(生成大量 CoT token),但准确率有质的飞跃。
7.5 实验高光时刻:屠榜!
7.5 实验高光时刻:屠榜!
MMMU (Reasoning)
Qwen3-VL-235B (Thinking)
MathVista (Math)
State-of-the-Art
DocVQA (Doc)
Near Perfect
* 数据来源:Table 2 from Qwen3-VL Technical Report. 对比模型包括 GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro.
全系列总结
从 Qwen-VL 的“初见光明”,到 Qwen2-VL 的“视力矫正”,再到 Qwen2.5-VL 的“精细入微”,最后到 Qwen3-VL 的“博闻强识、深思熟虑”。
这一路走来,我们见证了多模态模型如何一步步克服分辨率、位置编码、模态对齐、长上下文等技术瓶颈。Qwen3-VL 不仅是一个模型,更是一个集大成者,它代表了当前开源多模态模型的最高水平,也为通往 AGI 的道路点亮了一盏明灯。
7 八、实验与数据谱系 数字背后真正的故事:从刷榜到能力涌现
7
八、实验与数据谱系
数字背后真正的故事:从刷榜到能力涌现
📊 别只看 SOTA,要看“能力边界”的扩张
📊 别只看 SOTA,要看“能力边界”的扩张
同学们,当我们拿到一篇像 Qwen3-VL 这样厚重的技术报告时,最容易犯的错误就是直接翻到最后的表格,看一眼 "Bold"(加粗)的数字,然后感叹一句“哇,又 SOTA 了”,接着就把文章关掉了。
这是极其肤浅的阅读方式!
实验章节其实是论文中最诚实的部分。它不仅仅是在秀肌肉,更是在告诉你:我们到底教会了模型什么?它现在能做什么?它还在哪里跌倒?
"Benchmark 是模型能力的投影。如果我们把这些分散的数字连起来,就会看到一条清晰的进化曲线:从最基础的‘认字’(OCR),到‘看懂’(VQA),再到现在的‘思考’(Reasoning)。"
⛰️ 图解:Qwen-VL 系列的能力进阶金字塔
8.1 图像 Caption 与通用 VQA:基础能力的试金石
8.1 图像 Caption 与通用 VQA:基础能力的试金石
这就像是小学生的语文造句和看图说话。虽然简单,但它是所有复杂能力的基石。如果模型连图里有几个人、穿什么衣服都说不对,后面的推理就无从谈起。
🖼️ Zero-shot Captioning
在 Nocaps 和 Flickr30k 等数据集上,Qwen-VL 早期版本就已经表现出了惊人的泛化能力。这说明它的 Visual Encoder (ViT-bigG) 和对齐层 (Adapter) 确实把图像特征翻译成了 LLM 能听懂的语言。
❓ General VQA
VQAv2, GQA, OKVQA。这些任务考察的是“定位+识别”。Qwen3-VL 在这里的分数提升,更多归功于它在预训练阶段见过了海量的真实世界图像(World Knowledge),不再只是只会看 ImageNet 的书呆子。
8.2 文档理解与结构化抽取:从“认字”到“读懂逻辑”
8.2 文档理解与结构化抽取:从“认字”到“读懂逻辑”
这是 Qwen2.5-VL 和 Qwen3-VL 的绝对统治区。
💡 思考题:OCR 分数高 = 文档理解强吗?
有些模型 OCR 能跑 99 分,但在 DocVQA 上只能跑 60 分。为什么?
因为 OCR 只是把字认出来(Perception),而 DocVQA 需要你理解布局(Layout)、表格结构(Table
Structure)以及跨行跨页的语义关联。
比如:“请问表格第三行第二列的数字减去第一行第二列是多少?” 这需要极其精确的 spatial awareness。
| Benchmark | Task Description | Qwen3-VL Performance | Key Enabler |
|---|---|---|---|
| DocVQA | 扫描文档问答 | 96.5 (SOTA) | Native Dynamic Res (清晰度) |
| ChartQA | 图表数据分析 | 90.3 | High-res Input + CoT |
| InfoVQA | 复杂信息图理解 | 89.5 | DeepStack (深层语义) |
8.X 秘密武器:The Synthetic Data Factory (数据工厂)
8.X 秘密武器:The Synthetic Data Factory (数据工厂)
为什么 Qwen2.5-VL 能看懂那么复杂的 HTML 网页和 PDF?难道是找了一百万个标注员手写的吗?
当然不是。 它的秘密武器是一个全自动的“合成数据工厂”。
🏭 The Data Synthesis Pipeline
💡 核心逻辑:
既然标注真实文档很难,不如我们自己生成文档?
1. 拿干净的 Markdown / LaTeX 文本。
2. 用浏览器渲染引擎(Chrome/Puppeteer)把它渲染成图片。
3. 因为渲染过程是我们控制的,所以我们天然知道每一个字、每一个表格格子的精确坐标 (Bounding Box)。
这样,我们就得到了无限量的、完美标注的 OCR 和 Layout 数据!
8.3 视频理解:挑战“大海捞针” (Needle In A Haystack)
8.3 视频理解:挑战“大海捞针” (Needle In A Haystack)
在视频领域,Qwen3-VL 做了一个非常硬核的测试:Video Needle-in-a-Haystack (NIAH)。 这不仅是看模型能不能记住视频,而是看它在面对 1 小时长的视频(数万帧)时,能不能精准找到那一帧里的微小细节。
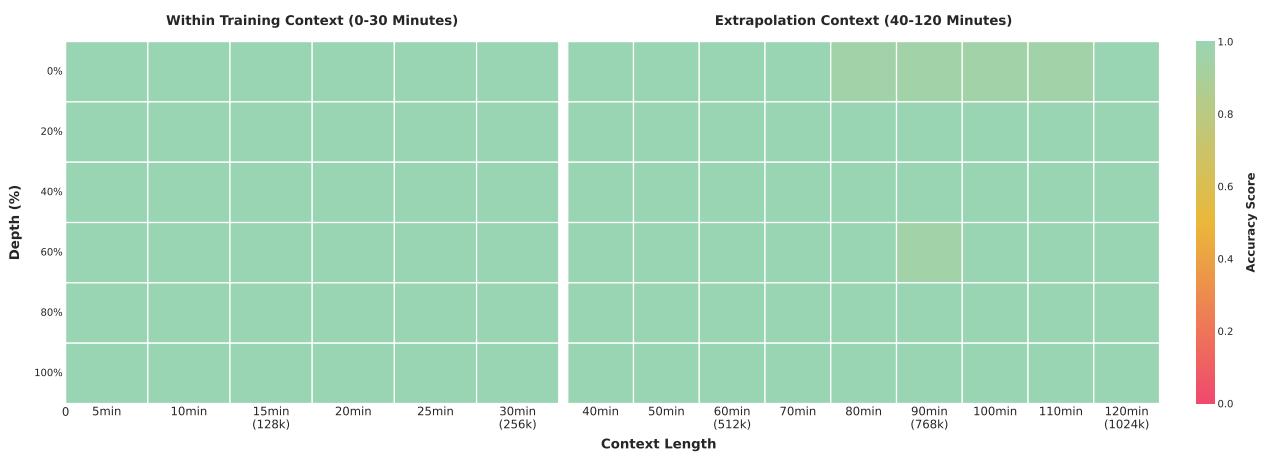
Figure 3: 视频大海捞针测试热力图。全绿代表 100% 召回。
📊 实验解读
看左边的热力图,几乎全是绿色。这意味着:
即便视频长度达到 30 分钟甚至 1 小时(Context Length 拉满),Qwen3-VL 依然能精准定位到任意时刻发生的事件。
功臣是谁?
1. Interleaved MRoPE:保证了时间维度在长序列中不丢失高频信息。
2. Text-based Timestamp:显式的时间戳 Token 提供了强有力的锚点。
8.4 多模态推理:Thinking Mode 的降维打击
8.4 多模态推理:Thinking Mode 的降维打击
这是 Qwen3-VL 最激动人心的部分。在 MMMU、MathVista 这种硬核推理 Benchmak 上,Qwen3-VL 的 Thinking 模式展现出了惊人的实力。
🕸️ 多模态推理能力雷达图
注意看 MathVista 和 MMMU 的分数。Qwen3-VL 在开启 Thinking 模式后,能够生成长达数千 token 的推理步骤,这极大地提升了它处理复杂几何题和物理题的能力。
一个关键的 Insight:
我们发现在训练中加入专门的 CoT 数据(Chain-of-Thought),不仅提升了数学能力,还泛化到了代码生成和 Agent 规划任务中。这说明“推理能力”在深层语义空间是通用的。
本章小结
实验数据告诉我们,Qwen-VL 系列的每一次升级都不是简单的“参数堆砌”,而是针对特定痛点(分辨率、时间、推理)的架构级突围。
现在,你已经看懂了它的前世今生,也看懂了它为何强大。接下来,是时候把这个大家伙搬进你的项目里了。
8 九、复现与实践指南 把论文里的 Qwen-VL 搬进你的工程里
8
九、复现与实践指南
把论文里的 Qwen-VL 搬进你的工程里
🛠️ 别光看论文,跑起来才是真理
🛠️ 别光看论文,跑起来才是真理
读完前面的架构解析,相信你已经对 Qwen-VL 系列有了深刻的理论认知。但作为一名要把模型落地的工程师或研究员,你的脑海里可能还有三个终极问题:
选哪个版本?
2B/7B/72B? Qwen2.5 还是 Qwen3?
怎么调用?
多图、视频、长文档怎么塞进 prompt?
怎么微调?
我有私有数据,能不能让它更懂我的业务?
9.1 选型指南:像 RPG 选职业一样选模型
9.1 选型指南:像 RPG 选职业一样选模型
Qwen-VL 家族现在人丁兴旺,选错了模型就像法师加了力量点,费力不讨好。我为大家整理了一份“懒人决策树”。
Qwen2.5-VL-7B
性价比之王。能跑大多数 Demo,支持视频和文档。
Plan B: Qwen2-VL-2B (手机/树莓派)
你需要处理什么任务?
9.2 最小闭环代码:从像素到 Token
9.2 最小闭环代码:从像素到 Token
Talk is cheap, show me the code. 下面这是一段基于 Hugging Face transformers 库的最小推理代码。
注意看注释里的李老师划重点部分,那是坑最容易出现的地方。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
# [李老师划重点]:这里一定要加 device_map="auto",否则大模型可能爆单卡显存
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
device_map="auto"
)
# Processor 负责处理图片 Resize 和 Tokenization
# 它是 Qwen-VL 系列的“魔法黑盒”,自动处理 Dynamic Resolution
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "请详细描述这张图片里的内容。"},
],
}
]
# 准备输入:把图片像素转成 Tensor,把文本转成 Input IDs
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# [李老师划重点]:generated_ids 包含了输入+输出
# 所以解码时要切片,只解出新生成的 token,否则你会看到问题又被复读了一遍
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)9.3 进阶玩法:多图与长上下文
9.3 进阶玩法:多图与长上下文
📚 处理长文档 (PDF)
当你要把一个 10 页的 PDF 喂给模型时,不要傻傻地把每一页当成一张独立图片。
[Img Page 1]
[Img Page 2]
...
"请结合第1页的表格和第5页的结论,分析..."
技巧: 给每一页图片前面加一个文本锚点(Anchor),比如 Image 1: Page 1。这样模型在 Attention
时能更容易定位到特定页面。
🎬 处理长视频
视频抽帧是关键。Qwen2.5-VL 支持动态 FPS,但你得控制总 Token 数。
1 fps (for short clip)
0.1 fps (for long movie)
技巧: 利用 Qwen2.5-VL 的绝对时间编码特性,你可以在 Prompt 里问:“在 00:15 秒左右发生了什么?”,模型能利用时间戳精确回答。
9.4 微调实战:LoRA 是你的好朋友
9.4 微调实战:LoRA 是你的好朋友
不要一上来就全参数微调(Full Fine-tuning),除非你有几百张 A100。对于大多数垂直领域任务(比如医学影像报告、工业质检),LoRA (Low-Rank Adaptation) 足够了。
💡 微调避坑指南
- 冻结 ViT: 通常情况下,Visual Encoder 不需要动。它已经看过几万亿 token 的数据了,比你手头那几千张图更懂视觉。
- 只调 LLM 和 Projector: 把 LoRA 挂在 LLM 的 `q_proj`, `v_proj` 上,甚至只微调 MLP Merger (Projector),就能获得不错的领域适应性。
- 数据格式对齐: 你的微调数据必须严格遵守 ChatML 格式,包括 `<|vision_start|>` 等特殊 token,否则模型会“精神分裂”。
9.5 常见翻车现场 (Common Pitfalls)
9.5 常见翻车现场 (Common Pitfalls)
OOM (显存爆炸)
现象: 跑着跑着 CUDA Out of Memory。
原因: Qwen2-VL 是动态分辨率,如果你喂了一张 8K 的超大图,它会切出几千个 Token,瞬间撑爆显存。
解法: 在 process_vision_info 里设置 max_pixels 限制,或者手动
Resize 超大图。
复读机模式
现象: 模型不停地重复输出同一句话,或者输出乱码。
原因: 通常是 Prompt 格式不对,漏了 <|im_end|>,或者 system prompt
写得太离谱。
解法: 严格检查 apply_chat_template 后的字符串,确保特殊 Token 完整。
Ready to Build?
理论已经讲透,代码也给了 demo。现在的你,已经具备了驾驭 Qwen-VL 这个多模态巨兽的所有知识。
无论是做学术研究,还是开发下一个爆款 AI 应用,路就在脚下。
9 十、未来展望 多模态大模型的下一个“圣杯”在哪里?
9
十、未来展望
多模态大模型的下一个“圣杯”在哪里?
Qwen3-VL 已经把上下文推到了 256K,把推理推到了 Thinking Mode,这是否意味着多模态模型已经走到头了?
答案显然是否定的。恰恰相反,我们才刚刚站在山脚下。
如果我们把现在的模型比作一个刚学会“看图写作文”的高中生,那未来的模型应该是一个能“看懂电影、操作电脑、甚至预测未来”的超级特工。这一节,我们抛开具体的 benchmark,来聊聊那些真正值得我们去攻克的 Open Problems。
10.1 视觉效率的极限:Token 真的越少越好吗?
10.1 视觉效率的极限:Token 真的越少越好吗?
📉 现状与痛点
虽然 Qwen2.5-VL 引入了动态分辨率,但本质上还是在做“压缩”。一张 4K 的图被压成了几百个 Token,大量高频细节(纹理、微小瑕疵)不可避免地丢失了。
🚀 潜在突破口
-
✂️
Dynamic Pruning (动态裁剪) 推理时动态判断哪些 Patch 是背景,直接丢弃,只保留前景 Token。
-
🧱
Multi-granularity (多粒度 Token) 大片蓝天用一个“粗粒度 Token”表示,人脸用一百个“细粒度 Token”表示。
10.2 可解释性的进化:从“黑盒”到“玻璃盒”
10.2 可解释性的进化:从“黑盒”到“玻璃盒”
现在的 Thinking Mode 虽然能输出文本思考链,但它依然没法告诉我们:“你到底在看图片的哪一块?”
未来的多模态解释长什么样?
Visual Grounding in CoT
思考链不再只是文字,而是夹杂着 <box> 坐标。
"因为这个区域
[10,10,50,50] 是红色的..."
Temporal Attribution
在回答视频问题时,高亮时间轴上的关键片段。
"结论基于
00:15 到 00:20 的画面推断。"
Mechanism Interpretation
打开 DeepStack 的黑盒,看看每一层到底学到了什么视觉特征。
10.3 走向世界模型 (World Model):预测未来
10.3 走向世界模型 (World Model):预测未来
目前的 Qwen-VL 还是一个被动观察者:你给它看什么,它就分析什么。但真正的智能体(Agent)需要具备预测未来的能力。
Next Token Prediction
→ Next Frame
Prediction
如果模型不仅能预测下一个文字,还能预测下一帧画面,它就拥有了物理世界的常识。
Research Frontier
"Generative models are not just for creating pretty pictures. They are the engines of imagination, allowing agents to simulate outcomes before acting."
10.4 评测革命:从刷榜到真实场景
10.4 评测革命:从刷榜到真实场景
“当一个指标变成目标时,它就不再是一个好指标。” —— 古德哈特定律
现在的 Benchmark (MMMU, MathVista) 虽然难,但大多还是静态的“做题”。未来的评测应该更贴近动态的真实世界。
Long-term Stability
让模型连续运行 24 小时,或者处理 1000 轮对话。它会“发疯”吗?会遗忘之前的设定吗?
Interactive Env
把模型扔进 Minecraft 或者真实的 OS 环境里,看它能不能完成“创建一个新文件夹并重命名”这种简单但需要闭环的任务。
Visual Safety
针对 Visual Jailbreak 的防御能力。如果图片里藏着恶意指令,模型能识别并拒绝吗?
讲义结语
这篇超长的讲义到这里就结束了。我们从 Qwen-VL 的初次尝试,一路走到了 Qwen3-VL 的巅峰对决。
希望你在看完这些“李宏毅式”的讲解后,脑子里留下的不仅仅是那一堆枯燥的缩写(ViT, MRoPE, DeepStack),而是一幅鲜活的技术演进地图。
未来的路很长,但方向已经清晰。带上这份地图,去创造属于你自己的多模态 SOTA 吧!
A 附录一:数学直觉与可视化 不仅要背公式,更要看见数学的形状
A
附录一:数学直觉与可视化
不仅要背公式,更要看见数学的形状
很多同学一看到论文里的 Math Section 就头大,觉得那是写给外星人看的。
但其实,深度学习里的每一个 Loss Function,本质上都是在定义一种“物理力场”。
在这这一节,我们不搞复杂的求导证明,而是用几何直觉 (Geometric Intuition) 把 Qwen-VL 系列中最重要的四个数学概念画出来。我们要看看,这些公式到底是怎么像这就看不见的“手”,推着几百亿个参数跑来跑去的。
语言建模损失 (The Prediction Game)
语言建模损失 (The Prediction Game)
符号拆解
- xt : 我们希望模型预测出的“正确答案”(Ground Truth Token)。
- x<t : 历史上已经说过的所有话(Context)。
- V : 视觉信号(Visual Tokens),这是 LVLM 和 LLM 的最大区别。
物理直觉:拔河比赛
想象词表里有 100,000 个单词,每个单词是一个“坑”。模型手里有一个“球”(概率质量,总重为1)。
这个公式的目标就是:强迫模型把那个球尽可能多地扔进“正确答案”的坑里。
如果扔偏了(比如把“猫”预测成了“狗”),-log(P)
就会变得超级大(惩罚),反向传播一脚把参数踢回去。
图解:视觉信号 V 改变了 LLM 对 "Cat" 的预测概率。
对比学习损失 (The Magnet)
对比学习损失 (The Magnet)
直觉:派对找朋友
想象高维空间是一个巨大的舞池。
vi 是一张图片(比如“一只狗”),ti 是它的描述文本(“A cute
dog”)。它们是一对好朋友。
tj 是其他路人的描述(比如“A red car”)。
这个 Loss 就是一块磁铁:它要把好朋友 i-i 这一对使劲往一块吸(分子变大),同时把所有路人
i-j 使劲推开(分母变小)。
🤔 李老师的追问:
为什么分母要加所有
j?因为光把朋友拉近是不够的,如果不推开别人,最后所有点都会塌缩到同一个原点(Collapse),模型就学会了“大家都一样”,这也是一种作弊!
Embedding Space 中的引力与斥力
Grounding Loss (The Anchor)
Grounding Loss (The Anchor)
为什么需要两个 Loss?
在目标检测(Detection)或定位(Grounding)任务中,我们通常用两个指标来约束模型:
- L1 Loss: 简单粗暴的“距离感”。计算预测框四个角点坐标和真实框的绝对差值。这就像是用一根弹簧把预测框硬拉向真实框。
- GIoU Loss: 更高级的“形状感”。单纯靠 L1 可能导致两个框虽然中心近了但完全没重叠。IoU 关注重叠面积,GIoU 解决了不重叠时梯度为 0 的问题。
黄色弹簧代表 L1 Loss,灰色虚线框用于计算 GIoU。
RoPE / M-RoPE 的几何本质 (The Clock)
RoPE / M-RoPE 的几何本质 (The Clock)
RoPE (Rotary Positional Embedding) 是所有 Qwen 模型的基石。
它的核心思想是:位置不是加法,而是旋转。
如果不加位置编码,Token 就像一堆散落在桌子上的词;
加上 Absolute PE,就像给每个词贴了个号码牌;
加上 RoPE,就像给每个词装了一个“时钟”。第 $m$ 个位置的词,它的向量在空间中旋转了 $m \times \theta$ 的角度。
// R_m 是一个旋转矩阵
🔍 M-RoPE 的直觉扩展:
如果你理解了这个二维旋转,那么 M-RoPE 就很好理解了:它只是把向量切成了三段,分别在三个正交的平面上旋转。
一段代表时间 $t$ 轴旋转,一段代表高度 $h$ 轴旋转,一段代表宽度 $w$ 轴旋转。
B 附录二:AI4S 专属速查表 当 Qwen-VL 穿上白大褂:从细胞到星系
B
附录二:AI4S
专属速查表
当 Qwen-VL 穿上白大褂:从细胞到星系
🧬 为什么科学家需要多模态大模型?
🧬 为什么科学家需要多模态大模型?
各位同学,在 AI for Science (AI4S) 领域,我们经常处理的是极其抽象的数据:基因序列、蛋白质结构、病理切片。 传统方法(如 CNN、U-Net)擅长输出“概率”或“分割掩码”,但它们无法“解释”它们看到了什么。
Qwen-VL 系列的价值在于:它能把显微镜下的视觉信号 (Pixel) 翻译成生物学家的语言 (Text/Code)。
本附录将手把手教你:如何把 Qwen-VL 变成你的“全天候 AI 实验员”。
B.1 科研场景映射表:你的任务适合哪个模型?
B.1 科研场景映射表:你的任务适合哪个模型?
| 科研任务 (AI4S Task) | 典型场景 | 推荐模型 | 核心理由 |
|---|---|---|---|
|
🧫 Cell2Sentence
|
单细胞形态学分析 Drug Screen Phenotyping 由图像生成细胞状态描述 |
Qwen2-VL-7B | 单细胞图像通常分辨率适中,但需要较强的语义对齐能力。7B 是性价比首选,微调成本低。 |
|
🗺️ HE to ST
|
从 H&E 染色切片预测空间转录组 病理区域定位 (Tumor Region) |
Qwen2.5-VL | 关键! 病理切片 (WSI) 往往是亿级像素。Qwen2.5-VL 的 Native Dynamic Resolution 能处理超大分辨率切片而不丢失细胞级细节。 |
|
🤖 Lab Agent
|
自动化实验室机器臂控制 读取老旧仪器屏幕数值 实验记录电子化 |
Qwen2.5-VL | 依赖极强的 OCR (读仪器) 和 Grounding (定位试管位置) 能力。Qwen2.5-VL 在这方面是目前的 SOTA。 |
|
📑 Literature Mining
|
从 PDF 论文中提取分子式 解析实验数据图表 (ChartQA) Meta-analysis |
Qwen3-VL | 需要 DeepStack 带来的超长上下文(吃透整篇论文)和 Thinking Mode(推理复杂的实验逻辑)。 |
B.2 深度图解:当 Qwen-VL 遇到病理切片 (HE to ST)
B.2 深度图解:当 Qwen-VL 遇到病理切片 (HE to ST)
在 Spatial Transcriptomics (ST) 任务中,我们希望从廉价的 H&E 染色图像推断出昂贵的基因表达空间分布。传统的做法是训练一个 CNN 回归模型,但 Qwen-VL 提供了一种“语义级”的新思路。
🔬 Workflow: From Tissue to Text & Gene
👨🏫 李老师的小黑板:
不要把 Qwen-VL 仅仅当成一个“聊天机器人”。在 HE to ST 任务中,你可以微调 Qwen,让它学会:
输入:[H&E Image] <|vision_start|>...<|vision_end|> "Locate regions with high CD8+ expression"
输出:
这相当于把一个复杂的回归问题(Regression),转化成了一个多模态模型最擅长的定位问题(Grounding)。
B.3 科研选型决策树:别用核弹打蚊子
B.3 科研选型决策树:别用核弹打蚊子
🔬 AI4S Model Selector
👉 Qwen2.5-Coder / Math
不需要视觉模块。用数学/代码微调版处理序列逻辑更好。
如果需要根据多篇论文的图表进行综合推理,或者需要规划多步化学合成路线:
🚀 必须上 Qwen3-VL (Thinking Mode)
只有 Thinking Mode 的 CoT 能力才能处理这种 System 2 级别的科研难题。
B.4 李老师的科研锦囊 (Tips for AI4S)
B.4 李老师的科研锦囊 (Tips for AI4S)
💡 关于分辨率的“迷思”
做病理分析时,不要把 10000x10000 的 WSI 直接塞进去!即使是 Qwen3-VL 也吃不消。
正确做法: 使用滑动窗口(Sliding Window)切成 1024x1024 的 Patches,利用 Qwen 的 Batch
处理能力生成局部描述,最后再用 LLM 汇总。
💡 活用 "Visual Prompting"
如果你想让模型关注细胞核,可以在图片上叠加半透明的红色圆圈(Visual Prompt)。Qwen-VL 对这类视觉提示非常敏感,比纯文字描述“看那个圆圆的东西”效果好得多。
💡 别忘了微调 (LoRA)
生物医学领域的术语(如 "Apoptosis", "Fibrosis")在通用语料中出现频率不高。用几百条专业标注数据跑一个 LoRA,能让模型的“专业黑话”水平突飞猛进。
💡 结构化输出是关键
不要让模型写散文!在 Prompt 里强制要求输出 JSON 格式(例如提取实验参数)。Qwen2.5-VL 在指令遵循上非常强,能保证输出的数据可以直接被 Python 脚本解析。
C 附录三:多模态黑话大辞典 (The LVLM Ultimate Glossary)
C 附录三:多模态黑话大辞典 (The LVLM Ultimate Glossary)
这不仅仅是一个名词解释表,更是一个「Qwen-VL 宇宙的百科全书」。我们收录了从 Qwen-VL 到 Qwen3-VL 所有的关键组件、模型型号和技术术语,助你彻底读懂技术报告。
🌳 Model Family (家族谱系)
🌳 Model Family (家族谱系)
Qwen-VL
Backbone: Qwen-7B
初代版本。基于 Qwen-7B,使用 OpenCLIP ViT-bigG,固定分辨率 448x448。奠定了“三阶段训练”的基础。
Qwen2-VL
Backbone: Qwen2 (2B/7B/72B)
二代进化。引入了 Naive Dynamic Resolution 和 M-RoPE,支持任意分辨率和长视频理解。
Qwen2.5-VL
Backbone: Qwen2.5 (3B/7B/72B)
细节狂魔。使用 Native Dynamic ViT,引入 Absolute Time Encoding,在文档和 Agent 任务上大幅增强。
Qwen3-VL
Backbone: Qwen3 (Dense & MoE)
终极形态。支持 256K Context,引入 DeepStack 和 Thinking Mode。拥有 235B MoE 版本。
👁️ Vision Encoders (视觉之眼)
👁️ Vision Encoders (视觉之眼)
ViT-bigG
Used in: Qwen-VL
Source: OpenCLIP (laion-2b)
Params: ~1.9B
特点: 巨型 ViT,擅长细粒度特征,但只支持固定分辨率。
Qwen2-ViT (600M)
Used in: Qwen2-VL
Source: Trained from scratch (based on SigLIP)
Params: ~600M
特点: 支持 Naive Dynamic Resolution,将输入 resize 为 14x14 的倍数。
Native Dynamic ViT
Used in: Qwen2.5-VL
Source: Trained from scratch
特点: 彻底抛弃 Padding,原生支持变长序列输入。引入 Window Attention 降低计算复杂度。
SigLIP-2
Used in: Qwen3-VL
Variant: SigLIP2-SO-400M / SigLIP2-Large
特点: Google 提出的改进版图文对齐模型,多语言能力强,是 Qwen3-VL 的视觉初始化基座。
🏗️ Core Architecture (核心组件)
🏗️ Core Architecture (核心组件)
C-Attn Adapter
(Qwen-VL) 单层 Cross-Attention,将不定长视觉特征压缩为固定 256 个 Token。
MLP Merger (C-Former)
(Qwen2-VL+) 使用 2x2 Pooling + MLP,将相邻的 4 个 Patch 特征融合成 1 个 Token。简单高效,保留空间结构。
DeepStack
(Qwen3-VL) 多层视觉注入。不仅在输入层,还在 LLM 的中间层注入视觉特征,解决深层网络“遗忘”视觉信号的问题。
SwiGLU
一种激活函数 (Activation Function)。比 ReLU 更平滑,能学习更复杂的非线性关系。Qwen 全系列的标配。
RMSNorm
Root Mean Square Normalization。一种归一化层,去掉了 LayerNorm 中的 Mean 计算,速度更快,训练更稳。
GQA
Grouped Query Attention。分组查询注意力。在推理时大幅减少 KV Cache 的显存占用,加速生成。
MoE
Mixture of Experts。混合专家模型。Qwen3-VL 有 30B-A3B 版本(总参数 30B,激活 3B),推理极快。
FlashAttention-2
底层加速库。Qwen2-VL 依赖它的 VarLen 特性来实现动态分辨率的高效计算。
🧭 Positional Encodings (位置编码)
🧭 Positional Encodings (位置编码)
RoPE
Rotary Positional Embedding
将位置信息编码为向量的旋转角度。具有良好的相对位置感知能力,是现代 LLM 的标配。
M-RoPE
Multimodal RoPE
(Qwen2-VL) 将 RoPE 扩展到 3D。Embedding 向量被切分,分别编码 Time (t), Height (h), Width (w)。
Interleaved M-RoPE
Qwen3-VL Upgrade
(Qwen3-VL) 为了解决原版 M-RoPE 的频谱失衡(时间维度只占高频),将 t, h, w 交错分布在整个 embedding 维度上。
Absolute Time Encoding
Text-based Timestamp
(Qwen2.5/3-VL) 不再完全依赖 Position ID,而是插入形如 <00:05> 的文本 Token 来显式标记时间。
📚 Data & Tasks (数据与任务)
📚 Data & Tasks (数据与任务)
Image Captioning
看图说话。Qwen 使用大规模合成数据(Recaptioning)来提升 Caption 的详细程度。
VQA
Visual Question Answering。看图答题。DocVQA (文档), ChartQA (图表), InfoVQA (信息图) 是现在的重点。
Grounding / Referring
视觉定位。输入文本,输出 Bounding Box。Qwen2.5-VL 进一步支持了 Point (点) 和 Counting (计数)。
OCR
Optical Character Recognition。文字识别。Qwen-VL 强调多语言 OCR 能力。
Interleaved Data
图文交错数据。类似 PDF 或网页,文字和图片穿插出现。训练模型处理多图上下文和指代关系。
Long-CoT Data
长思维链数据。包含详细推理步骤的数学题或逻辑题。用于训练 Thinking Mode。
Hallucination
幻觉。模型一本正经地胡说八道(比如描述了图里没有的物体)。
Zero-shot
零样本。模型在没有针对特定任务微调的情况下,直接完成任务。
D 附录四:灵魂拷问 Q&A (李老师答疑时间)
D 附录四:灵魂拷问 Q&A (李老师答疑时间)
这里收集了一些大家在复现、训练或部署 Qwen-VL 时最常问到的“扎心”问题。我们不打官腔,直接上干货。
Q1:显存实在不够,量化 (Quantization) 会让模型“瞎眼”吗?
👨🏫 李老师: 这是一个非常好的问题。
一般来说,Int4 / Int8 量化 对语言理解能力的影响是可以接受的(只会稍微变笨一点点)。但是!对于视觉编码器
(ViT),请尽量保持半精度 (BF16/FP16),不要量化!
最佳实践: LLM 量化到 Int4,ViT 保持 BF16。
Q2:如果我要微调,数据配比 (Data Mixture) 怎么设才不会“灾难性遗忘”?
👨🏫 李老师: 这个问题是多模态微调的“玄学”核心。
如果你只用纯文本微调,视觉能力会掉;如果你只用纯图片微调,语言能力会掉。经验法则如下:
- 领域微调: 你的业务数据(如医疗问答)。
- 通用图文 Replay: 必须混入约 10% - 20% 的通用图文数据(如 COCO Caption, VQAv2)。这叫 "Regularization"(正则化),防止模型忘掉基础视觉能力。
- 纯文本 Replay: 如果你很在意模型的纯聊天能力,最好也混入一点纯文本对话数据。
Q3:Thinking Mode (CoT) 真的能提升性能吗?还是只是废话文学?
👨🏫 李老师: 对于简单任务(比如“图里有只猫”),CoT 确实可能是废话,甚至会因为输出太长导致幻觉。
但是!对于复杂推理任务(比如“算出图中三角形的面积”、“分析这张财报的趋势”),CoT 是质变。
LLM 本质上是在做概率预测。如果不让它先生成中间步骤(Thinking),它就得在一步之内直接预测出最终答案,这太难了。CoT
相当于给了模型“打草稿”的空间,让它把复杂问题拆解成简单问题,从而降低了预测难度。
在 Qwen3-VL 中,Thinking Mode 让 MathVista 这种数学题的分数提升了巨大的幅度,这就是证明。
Q4:处理视频时,FPS 到底设多少合适?
👨🏫 李老师: 别被 FPS 框死,要看Token 预算。
视频处理的核心矛盾是:信息量 vs. 显存。
- 短视频 (Tik Tok): 可以高 FPS (比如 1~2 fps),保留动作细节。
- 长电影 (2小时): 必须极低 FPS (比如 0.1 fps,甚至关键帧提取),否则上下文直接爆炸。
- Qwen2.5-VL 的优势: 它是动态分辨率 + 绝对时间编码。你可以混合输入:关键时刻用高分辨率多帧,平淡时刻用低分辨率少帧。只要时间戳(Timestamp)对上了,模型就能看懂。
Q5:我看论文里的 CIDEr、Rouge 分数很高,但为什么我在实际用的时候感觉没那么神?
👨🏫 李老师: 欢迎来到真实世界!
传统的 NLP 指标(如 Rouge, BLEU, CIDEr)主要是比对 N-gram 重合度。但在多模态任务里,它们往往失效了。
比如:
GT: "A white dog."
Pred: "A cute puppy with snowy fur."
这两个句子语义完全一致,但 N-gram 重合度很低,导致 Rouge 分数很低。
现在的趋势: 大家更看重基于 LLM 的评测(如 LLM-as-a-Judge)或者针对特定能力的 Benchmark(如
MathVista 测数学,DocVQA 测文档)。不要迷信单一指标,要多看几个维度的榜单。
结语:Build Your Own Eyes
结语:Build Your Own Eyes
这篇漫长的旅程终于要结束了。
从 Qwen-VL 的初次尝试,到 Qwen3-VL 的巅峰对决,我们看到的不仅是一个模型家族的进化史,更是AGI 感知模块的进化史。
"The eye altering alters all." —— William Blake
当模型拥有了更清晰的视力(Dynamic Resolution),它就能看到文档的细节; 当模型拥有了更长的时间记忆(M-RoPE + Long Context),它就能理解视频的因果; 当模型拥有了深层思维(Thinking Mode),它就能推导出画面背后的逻辑。
但这依然不是终点。真正的物理世界模型、具身智能(Embodied AI)、实时交互... 还有无数的 Open Problems 等着你们去解决。
现在,把这份讲义关掉,打开你的 IDE,去 Hugging Face 下载权重,去跑通第一个 Demo。
动手,才是学习深度学习的唯一捷径。