AI: 驱动科学发现的第四范式
一份面向未来医学科学家的交互式讲义
编撰者:纪家灏 | 复旦大学上海医学院 19级八年制
引言:站在科学革命的门槛上
计算机技术的诞生给科学领域带来了一次革命,它使得之前许多认为不可能的计算任务变为可能,让繁复的计算不再成为阻碍科学发展的因素。不仅仅计算机科学促进了别的学科的科学进步,其他领域的科学进步也会反过来为计算机科学的问题提供新的解决思路。而其中可能很少人会想到,人工智能的相关成果,也可以应用到医学科学里面。而且,它甚至可能会给医学科学带来一个新的纪元。
长期以来,AI常常与自动驾驶、语音助手或棋盘游戏联系在一起。然而,其在科学研究领域的应用,尤其是医学科学,正掀起一场更为深远、更为静默的革命。它不再仅仅是一个提高效率的“工具”,而是正在演变为一种全新的科学研究“范式”。科学哲学家托马斯·库恩提出,科学的进步并非线性累积,而是通过一系列“范式转移”来实现的。每一次转移,都意味着我们观察世界的基本框架、研究问题的方法论以及评价真理的标准发生了根本性的改变。历史上,科学研究已经历了三次重大的范式演进。今天,我们有幸共同见证并参与第四范式的诞生。
本讲义旨在系统性地阐述“AI作为科学发现第四范式”的核心思想。我们将一同回顾科学方法的进化历程,理解AI为何在此时此刻成为历史的必然选择;我们将深入探讨AI的“世界观”——“万物皆可数据化”,以及它的核心工作原理;最后,我们将通过一系列前沿的医学研究案例,具体展示AI作为精准的“预测引擎”和敏锐的“假设生成器”,正在如何加速从基础研究到临床转化的全过程。
无论你未来是成为一名临床医生、一名基础研究科学家,还是像我一样想成为一名医生科学家,理解并掌握这一新范式,都将是你开启未来医学科学大门的钥匙。让我们一同踏上这场探索之旅。
第一章:科学方法的进化——从牛顿、孟德尔到深度学习
要理解第四范式的革命性,我们必须首先回顾它的前辈们是如何为之铺平道路的。科学的本质是构建现实世界的简化模型,以理解其运行规律并做出预测。随着我们探索的边界从宏观宇宙深入到微观的细胞内部,我们构建模型所使用的“语言”和“工具”也必须随之进化。
1.1 第一范式:经验科学 (Empirical Science)
这是最古老的科学范式,源于数千年前人类对自然世界的观察和归纳。其核心是实验和观测。从亚里士多德对动植物的分类,到近代实验科学的奠基,这一范式的特点是处理相对简单、线性的因果关系。
经典案例:孟德尔的豌豆实验
在生物学研究的过程中,遗传是必不可少的一个环节,比如在孟德尔的豌豆杂交实验中,他将整个遗传现象简化为几个独立的、可控的变量(如豆粒的颜色、形状)。因此,在这样的实验中,有一个问题是亟待解决的:我们如何快速地得知所杂交的植株在遗传中的位置以确认它所对应的表型?孟德尔的研究一次性大概会产生许多组数据,里面包含着数十种杂交组合,而它的目标匹配往往是成百上千的实验记录,在这两个体量都很庞大的数据集中进行匹配搜索就好像同时在搜索引擎上搜索数十万次,这里面所需的算力是不可想象的。不过,因为当时的数据量还不大,孟德尔通过严密的逻辑推理和巧妙的实验设计,就足以发现其背后的规律。这是人类智慧在处理低维度、清晰因果关系问题上的胜利。
1.2 第二范式:理论科学 (Theoretical Science)
随着观测工具的进步,科学家们积累了大量无法用简单经验归纳来解释的数据。此时,理论科学应运而生。它不再满足于描述“是什么”,而是试图用一套普适的、抽象的数学公理和模型来解释“为什么”。
经典案例:牛顿的万有引力和爱因斯坦的相对论
牛顿并未亲身“观察”到引力本身,但他构建了一个优美的数学模型(F = G(m1*m2)/r^2),这个模型不仅完美解释了当时已知的行星运动规律,还精准预测了未知天体的存在。爱因斯坦的相对论更是将理论思辨推向极致。这是科学的第二次飞跃:从具体观测上升到抽象理论,用简洁的数学公式描绘宇宙的宏大图景。
1.3 第三范式:计算与统计科学 (Computational & Statistical Science)
进入20世纪后半叶,计算机的出现为科学研究带来了第三次革命。一方面,对于那些理论模型过于复杂、无法求得解析解的问题(如天气预报、流体力学),我们可以通过强大的计算能力进行模拟仿真。另一方面,面对生物学等领域涌现出的海量、充满噪声的数据,传统的人脑推理和简洁的理论模型都显得力不从心。此时,统计学成为了连接数据与结论的桥梁。
核心应用:全基因组关联分析 (GWAS)
进入21世纪,随着人类基因组计划的完成和测序成本的指数级下降,我们首次有能力系统性地探究常见复杂疾病(如糖尿病、高血压)的遗传基础。GWAS正是为解决这类“多因一果”问题而设计的核心统计工具。
它的核心思想非常直观:比较“病例组”和“对照组”人群基因组中数百万个遗传变异位点(SNPs)的频率。如果某个SNP在病例组中出现的频率显著高于对照组,我们就认为它与疾病存在统计学上的关联。其结果通常用“曼哈顿图”来可视化,图中每一个点代表一个SNP,Y轴越高代表其与疾病的关联越强。那些最显著的信号就像摩天大楼一样拔地而起,整个图形酷似纽约曼哈顿的天际线,因而得名。
第三范式的局限性:
GWAS等统计学方法是巨大的进步,但它的局限性也日益凸显:它大多只能告诉我们“哪里”有关联,却难以解释“为什么”以及基因间的复杂交互作用。正是在第三范式遇到瓶颈之时,我们迎来了处理高维度、非线性系统的更强武器——人工智能。
第二章:AI的世界观——万物皆可数据化
现在我们知道,科学的发展需要一种能处理海量复杂数据的新方法。AI之所以能够扮演这个角色,其最根本的前提在于,它拥有一种独特的“世界观”:世间万物,皆可被表示为数据。
要让机器理解并处理复杂的生物学问题,我们必须首先学会将这些问题“翻译”成机器能够理解的语言——结构化的数据。这种“翻译”或“表示”(Representation)的过程,是整个AI for Science领域的基石。不同的生物实体,其内在结构决定了最适合它的数据表示方法。
2.1 基因组学 (Genomics):生命密码即序列
-
数据表示:字符串 (String) / 序列 (Sequence)
一条DNA或RNA链,其核心信息就蕴含在A, T, C, G(或U)四种碱基的线性排列顺序中。这与人类语言中的字母排列成单词、句子和篇章,在结构上高度相似。因此,我们可以直接将基因序列表示为一个长字符串,如
"ATTCGATTACA..."。 -
AI模型:自然语言处理 (NLP) 模型,如Transformer
近年来在语言翻译、文本生成领域大放异彩的Transformer模型,其核心能力是捕捉序列中长距离的依赖关系(即一个词如何受到上文很远地方另一个词的影响)。这一能力恰好适用于基因组学:一个基因的功能可能受到数万个碱基对之外的一个增强子区域的调控。AI通过“阅读”海量基因序列,学习基因语言的“语法”和“语义”,从而预测基因功能、识别调控元件,甚至判断突变是否致病。
DNA序列处理流程
2.2 蛋白质组学 (Proteomics) 与药物发现:分子是社交网络
-
数据表示:图 (Graph)
一个蛋白质或小分子药物,其功能不仅取决于原子种类,更取决于它们在三维空间中如何连接和排布。这种“实体(原子)”与“关系(化学键)”的结构,可以被完美地抽象为一个数学上的“图”。在图中,每个原子是一个节点 (Node),每条化学键是一条边 (Edge)。
-
AI模型:图神经网络 (Graph Neural Network, GNN)
GNN是专门为处理图结构数据而设计的AI模型。它的工作方式非常巧妙,模拟了信息在网络中的传播过程。每个节点会不断地从它的邻居节点那里收集信息,并结合自身特征来更新自己的状态。经过几轮“信息传递”,每个原子节点都包含了其局部化学环境的丰富信息。这使得GNN能够精准地预测蛋白质的功能、识别药物与靶点的结合位点,甚至从零开始设计全新的分子结构。
graph TD;
A[Cα] -- 肽键 --> B(N);
A -- 侧链 --> C{R};
A -- 羰基 --> D[C=O];
B -- H --> E[H];
2.3 医学影像学 (Medical Imaging):影像是像素矩阵
-
数据表示:矩阵 (Matrix) / 张量 (Tensor)
无论是病理切片、CT扫描还是核磁共振(MRI),其在计算机中的本质都是一个由像素或体素构成的网格。一张黑白图片可以表示为一个二维矩阵,每个元素的值代表该像素点的灰度。一张彩色图片则是三维的,通常包含红(R)、绿(G)、蓝(B)三个通道的矩阵。
-
AI模型:卷积神经网络 (Convolutional Neural Network, CNN) / Vision Transformer (ViT)
CNN通过模拟生物视觉皮层的处理机制,使用“卷积核”(一种小型滑窗滤波器)来逐层扫描图像,从而有效地识别出图像中的边缘、纹理、形状等局部特征,并最终组合成高级语义概念(如“细胞核”、“肿瘤区域”)。近年来兴起的ViT则将图像分割成小块(patches),并借鉴Transformer处理序列的方式来分析这些图像块之间的全局关系。这些模型正在彻底改变放射科和病理科医生的工作流程,实现对肿瘤、病灶的自动检测、分割和良恶性判断。
一个直观的例子:用矩阵表示笑脸
想象一个8x8像素的黑白笑脸。我们可以用一个8x8的矩阵来表示它,其中1代表黑色像素,0代表白色像素。这个矩阵就是AI“看到”的世界。
第三章:AI的“大脑”——学习宇宙的映射规则
好,现在我们已经学会了把生物世界“翻译”成数据。那么,AI的核心任务究竟是什么?答案可以被一个看似简单的公式所概括,这个公式是理解现代AI科学的“第一性原理”:
Y = f(X)
这个公式描绘了一种映射关系 (Mapping)。X是输入(如基因序列),Y是输出(如疾病风险),而f是连接两者的自然规律。科学研究的核心目标,在很大程度上就是为了揭示和理解这个函数 f。在生命科学中,f 几乎总是无比复杂、高维且非线性的。
AI的任务,就是通过“阅读”海量的(X, Y)数据对,来构建一个尽可能逼近真实 f 的近似函数 f̂。
3.1 函数 f 的现代形式:神经网络
AI用来近似 f 的工具,就是人工神经网络 (Artificial Neural Network, ANN)。其灵感来源于生物大脑,由大量被称为“神经元”的简单计算单元相互连接而成。
它的学习过程(也叫“训练”)可以这样理解:
- 前向传播: 将一个已知的输入
X送入网络,让信号逐层传递,最终在输出层得到一个预测值Y_pred。 - 计算损失: 比较预测值
Y_pred和真实的标签Y_true之间的差距。这个差距被称为“损失”或“误差”。 - 反向传播与梯度下降: 这是最关键的一步。模型会计算出这个损失是由网络中哪些连接权重“贡献”的,然后朝着能让损失减小的方向,对这些权重进行微小的调整。这个过程就像一个蒙着眼睛的登山者想走到山谷最低点,他每走一步,都会用脚感受哪个方向是下坡最陡峭的方向(即梯度),然后朝那个方向迈出一小步。
- 迭代: 重复以上步骤亿万次,用海量的数据不断地“打磨”网络中的权重。最终,整个网络就学会了从
X到Y的精确映射。
第四章:AI的双重角色——预测引擎与假设生成器
一个训练精良的AI模型 f̂,如同一个掌握了某领域“独门绝技”的专家。在科学研究中,我们可以从两个层面来发挥它的巨大价值。
4.1 角色一:作为精准的“预测引擎”
这是AI最直接的应用。一旦我们拥有了函数 f̂,我们就可以进行大规模的、快速的、低成本的虚拟实验 (in silico experiment)。给定一个全新的输入 X_new,模型可以直接计算出其对应的预测结果 Y_pred。
例如,在药物发现中,我们可以将数百万种化合物的分子结构 X 输入到AI模型中,在几天之内就能预测出它们的活性和毒性 Y,然后只挑选出得分最高的几十个候选者进入实验室进行验证。这是一种革命性的效率提升。
4.2 角色二:作为敏锐的“假设生成器”
预测“是什么”固然重要,但科学的更深层追求是理解“为什么”。AI模型常常被批评为一个“黑箱”,我们只知道它的输入和输出,却不理解其内部的决策逻辑。然而,近年来发展的可解释性AI (Explainable AI, XAI) 技术,正致力于打开这个“黑箱”,让我们得以一窥其决策逻辑。
AI在做出判断时最关注的输入特征,本身就是高质量的、数据驱动的科学假设。例如,在分析病理图像时,XAI技术可以高亮出对模型判断“预后不良”贡献最大的细胞区域,这些区域可能就是人类病理学家此前未曾注意到的新生物标志物。
关键警示:相关性 (Correlation) ≠ 因果性 (Causation)
这是应用AI进行科学探索时必须时刻谨记的“第一天条”。AI极其擅长从数据中发现复杂的相关性,但它本身无法证明因果性。一个经典的例子是:数据显示,冰淇淋销量越高的日子,溺水死亡的人数也越多。两者强相关,但我们不能得出“吃冰淇淋导致溺水”的荒谬结论。真正的共同原因是“炎热的夏天”,它同时驱动了冰淇淋销量和游泳人数的增加。
第五章:前沿案例——第四范式在医学中的应用
理论的阐述最终需要通过实践来证明。以下三个案例,分别从不同角度展示了AI第四范式如何具体地应用于前沿医学研究。

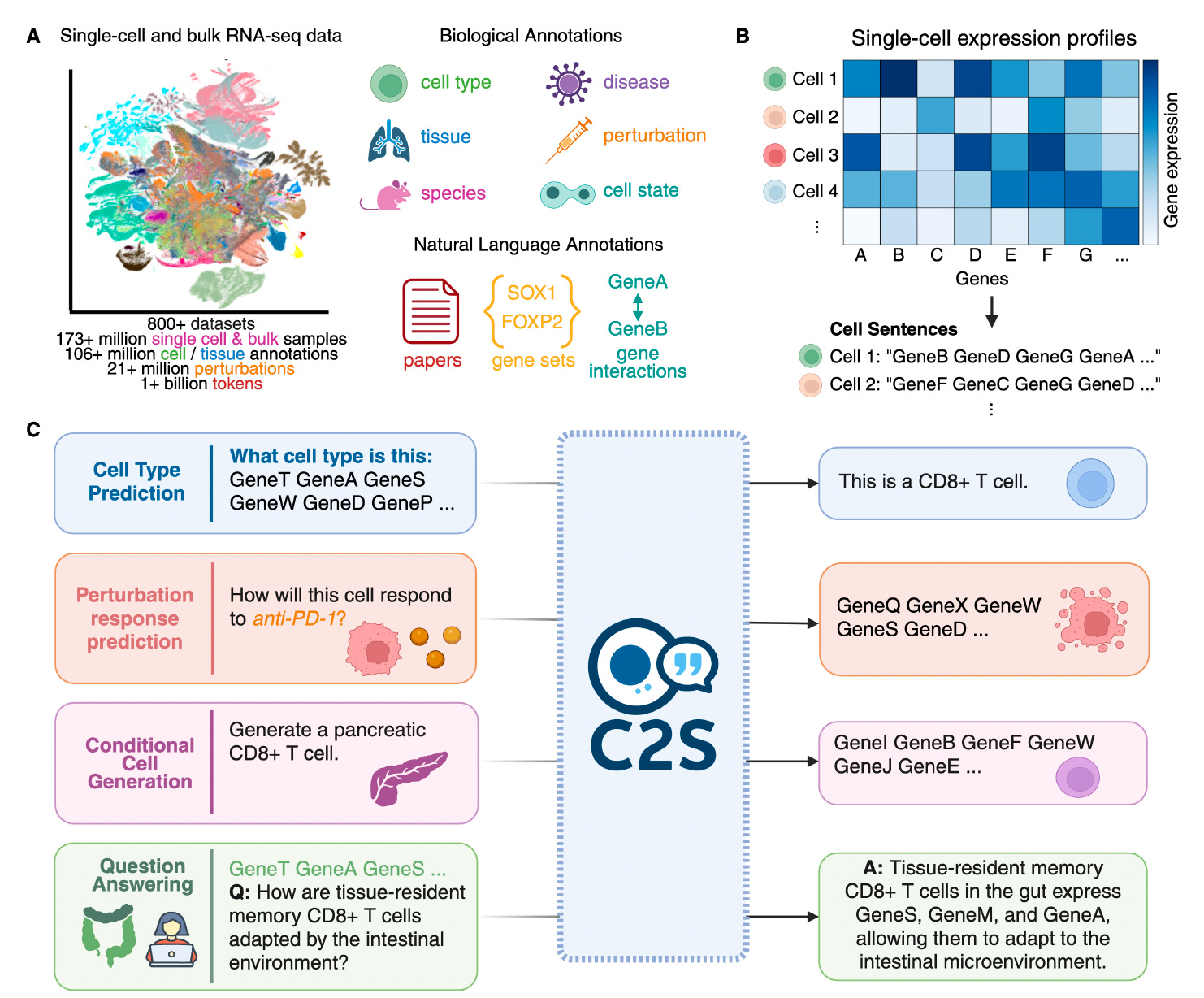
第六章:未来与你的角色——成为人机协作时代的医学科学家
AI第四范式并非科学的终点,而是一个全新的起点。它在带来巨大机遇的同时,也伴随着挑战:
- 数据挑战: 高质量、大规模、标注良好的数据集是训练强大AI模型的“燃料”。
- 伦理与偏见: 训练数据中的偏见会被AI模型“学会”并放大,导致医疗不公。
- 可解释性与信任: 在高风险的临床决策中,提升模型的可解释性是其走向应用的关键。
面对这样的未来,作为新一代的医学科学家,你的角色不再是与机器竞争,而是要成为一个善于与AI协作的“指挥家”。你需要具备的核心素养包括:
1. 深厚的领域知识
只有你才真正理解疾病的生物学机制和临床需求。AI无法取代你提出那个最关键、最富洞察力的科学问题。
2. 计算思维
你需要理解“万物皆数据”的原理,能够将一个复杂的生物学问题,拆解、抽象成一个AI可以处理的数据映射问题。
3. 批判性思维
你需要深刻理解AI的局限性,特别是“相关与因果”的区别。你的核心任务是设计最严谨的实验,去验证或推翻AI提出的假设。
未来的医学突破,将越来越多地诞生于人类智慧与机器智能的交汇点。AI将我们从繁重、重复的数据分析中解放出来,让我们能将宝贵的精力聚焦于最具创造性的环节:提出伟大的问题,设计优雅的实验,并对世界的本质做出更深刻的解释。
这,就是科学第四范式的承诺。欢迎你的加入。